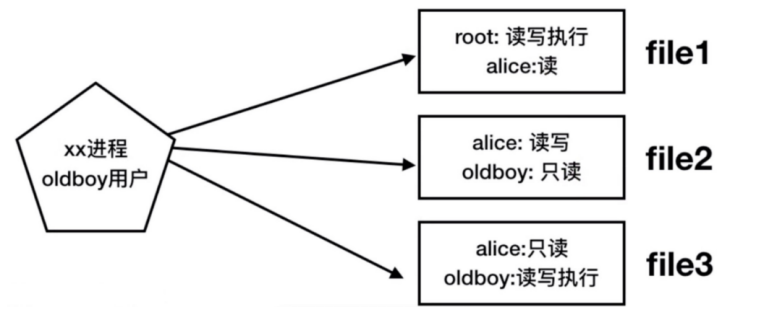
【1】Linux基础 1.网络相关 1 2 3 4 5 6 7 8 9 10 11 12 13 14 ip地址:设备之间互相通信 xxx.xxx.xxx.xxx 4 段 点分十进制 范围:0 -255 0 .0 .0 .0 -255 .255 .255 .255 子网掩码:划分网段,判断ip是否在同一个局域网内 255 .255 .255 .0 子网一样就是在同一网段 网关:让设备上局域网以外的网站,需要出网关(出国的海关)网关地址就是路由器的IP DNS:domain name server 域名解析服务 若子下面两个ip网掩码前三位一样,最后一位不一样,则前三位是网络位) 子网掩码 网络位 主机位 255.255.255.0 192 .168 .0 . 69 255.255.255.1 192 .168 .0 . 37 若子下面两个ip网掩码前两位一样,最后两位不一样,则前两位是网络位 子网掩码 网络位 主机位 255.255.0.241 192 .168 . 1 .5 255.255.1.67 192 .168 . 0 .241 Windows:cmd中 ipconfig -all查看ip
1.虚拟机的网络模式 1 2 3 4 5 桥接模式:将物理机的网卡和虚拟机的网卡连接在一块(网桥)作用:共享物理机的网络,让虚拟机的IP和物理机的IP在同一个网段(局域网) 192.168.10.142 192 .168 .10 .xxxNAT模式:将物理机的IP地址,动态转换成虚拟机的私网IP,这个私网IP也可以自定义 仅主机模式:将物理机看成是一个没有路由器的交换机,所有的虚拟机都连接在这个交换机上,所有虚拟机之间可以互相通信,但是无法上外网
NAT模式原理图
2.虚拟机网卡配置
3.系统内配置网卡 nmtui命令
命令行配置
4.Xshell连接不上虚拟机排查 1.查看虚拟机网卡配置
2.检查路由器 (虚拟网络编辑器)配置
3.虚拟机网卡配置文件内容
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 TYPE=Ethernet PROXY_METHOD=none BROWSER_ONLY=no BOOTPROTO=none none/dhcp/static DEFROUTE=yes IPV4_FAILURE_FATAL=no NAME=ens33 DEVICE=ens33 ONBOOT=yes 开机启动网卡 IPADDR=10.0.0.250 ip NETMASK=255.255.255.0 子网掩码 GATEWAY=10.0.0.2 网关 DNS1=223.5.5.5 首选DNS DNS2=223.6.6.6 备用DNS IPV6INIT=no UUID=c96bc909-188e-ec64-3a96-6a90982b08ad
4.测试虚拟机是否能上外网 ping baidu.com
1 2 3 ping baidu.com 在xshell里ping10.0.0.250,谁连接谁,就用谁去ping谁
5.检查下端口是不是22(ssh协议端口22)
telnet 10.0.0.250 22 [c:~]$ telnet 10.0.0.250 22
Windows开启telnet
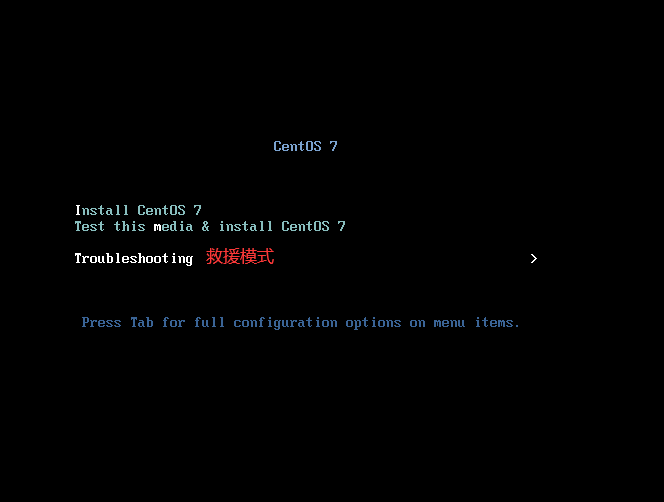
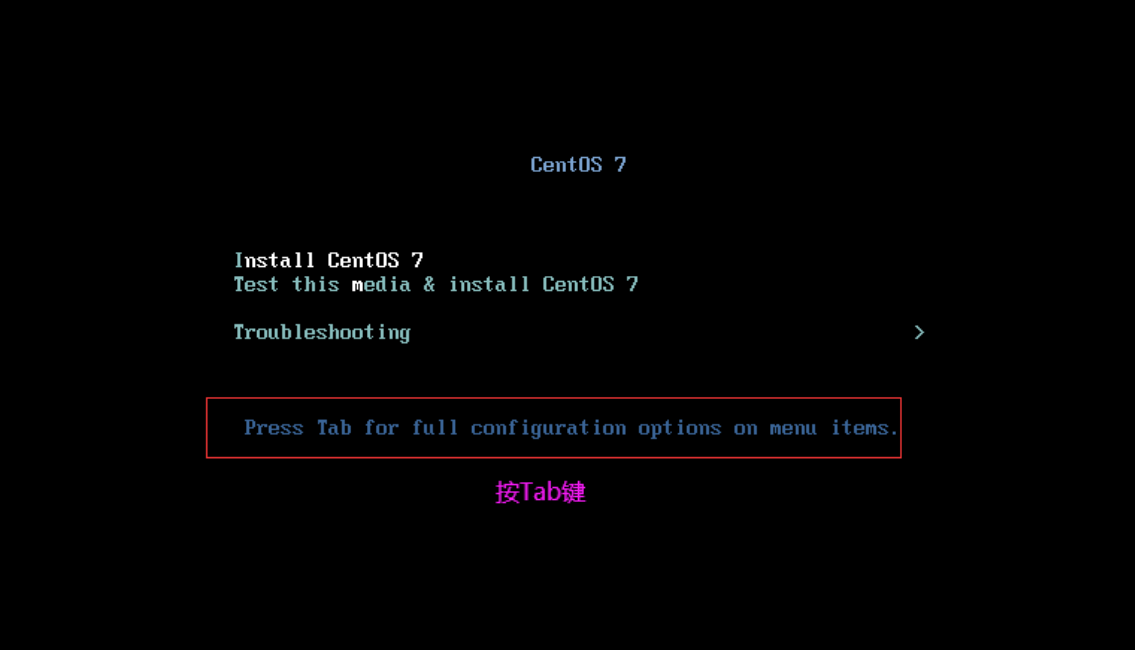
2.C6 & C7安装 1. Centos 6 安装
1.选第一个,回车
选择时区和填写密码等省略
选择base和develop工具
2.配置CentOS6网卡 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 [root@localhost ~]# vi /etc/sysconfig/network-scripts/ifcfg-eth0 DEVICE=eth0 HWADDR=00:0C:29:5A:FC:82 TYPE=Ethernet UUID=65c55f51-b929-49fa-b8c9-541e6230e11b ONBOOT=yes NM_CONTROLLED=yes BOOTPROTO=none IPADDR=10.0.0.10 NETMASK=255.255.255.0 GETEWAY=10.0.0.254 DNS=223.5.5.5 :wq 重启网卡 1./etc/init.d/network restart 2.service network restart
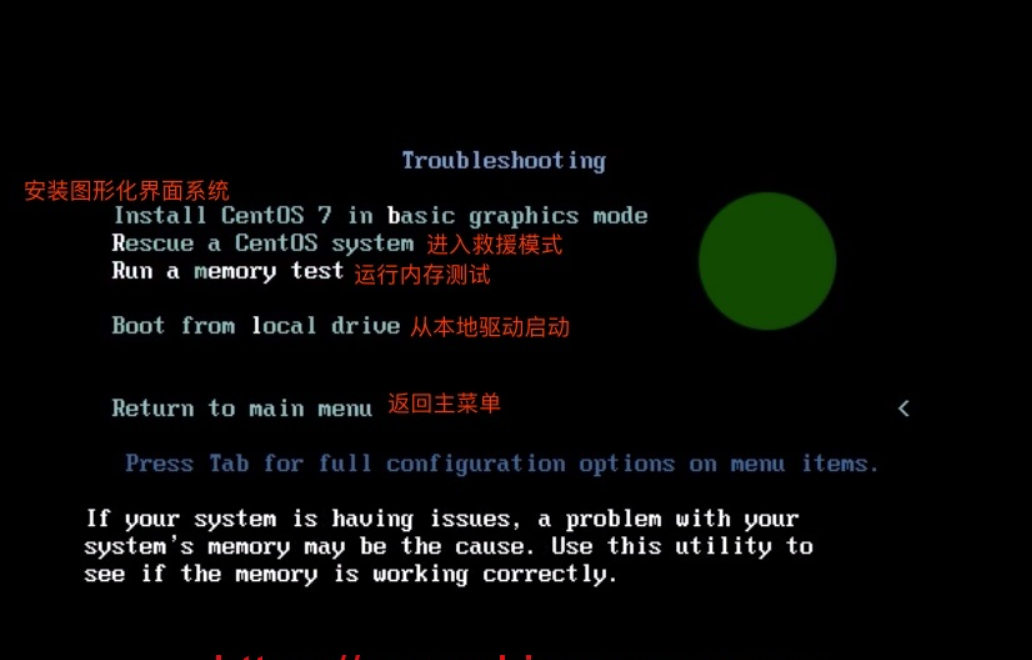
3.CentOS7安装
3.变量 1 2 3 4 5 6 7 8 9 10 11 12 13 14 变量名=变量值 age=18 [root@localhost tmp]# echo $age 18 1.echo '$oldboy' 结果是什么? $oldboy 2.echo '$name' 结果是什么? $name 3.echo "$name " 结果是什么? oldboy 4.1.echo "$oldboy ' 结果是什么? 空值 echo {1..5..2}每隔2个数在1-5取数
环境变量(系统变量)
1 2 3 4 5 [root@localhost ~] declare 1.[root@localhost ~]# ll /root/.bashrc 2.[root@localhost ~]# ll /etc/bashrc 3.[root@localhost ~]# ll /etc/profile 4.[root@localhost ~]# ll /etc/profile.d/
命令提示符变量
1 2 [root@localhost ~]# echo $PS1 [\u@\h \W]\$
1 2 3 4 5 6 7 修改环境变量文件永久生效 [root@lb01 ~]# vi ~/.bashrc /root/.bashrc [lgj@lb01 root]$ vi ~/.bashrc /home/lgj/.bushrc 若root用户修改 超级用户和普通用户家目录: 超级用户root:/root 普通用户:/home/普通用户名
BASH特性 BASH特性——Tab补全
BASH特性——快捷键
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 Ctrl + w Ctrl + z Ctrl + k Ctrl + u Ctrl + s Ctrl + q Ctrl + 左右 Ctrl + a Ctrl + e Ctrl + c Ctrl + l BASH特性——历史命令 BASH特性——命令别名 Ctrl + d Ctrl + r ESC + . '井号'
BASH特性——历史命令
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 [root@localhost ~]# history 1 age=18 2 echo age 3 echo "age" 4 jjjsjsjsjsjsjjsjjsjsjjjsjss 5 history [root@localhost ~]# history -w [root@localhost ~]# history -c [root@localhost ~]# history -d 4 [root@localhost ~]# !vi [root@localhost ~]# !! [root@localhost ~]# !10
BASH特性——命令别名
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 [root@localhost ~]# alias alias cp ='cp -i' alias egrep='egrep --color=auto alias ens33=' ip address show ens33' alias fgrep=' fgrep --color=auto' alias grep=' grep --color=auto' alias l.=' ls -d .* --color=auto' alias ll=' ls -l --color=auto' alias ls=' ls --color=auto' alias mv=' mv -i' alias net=' vi /etc/sysconfig/network-scripts/ifcfg-ens33' alias rm=' rm -i' alias which=' alias | /usr/bin/which --tty-only --read-alias --show-dot --showtilde' ## 设置别名(增)临时 alias 别名=' 命令' [root@localhost ~]# alias ens33=' ip address show ens33' ## 删除别名(删) unalias 别名 [root@localhost ~]# unalias ens33 ## 修改别名(改) alias 别名=' 命令' alias net=' vi /etc/sysconfig/network-scripts/ifcfg-ens34[root@localhost ~]# vi ~/.bashrc alias net='vi /etc/sysconfig/network-scripts/ifcfg-ens33'
BASH特性——获取命令帮助
1 2 3 man 命令 命令 --help http://linux.51yip.com/
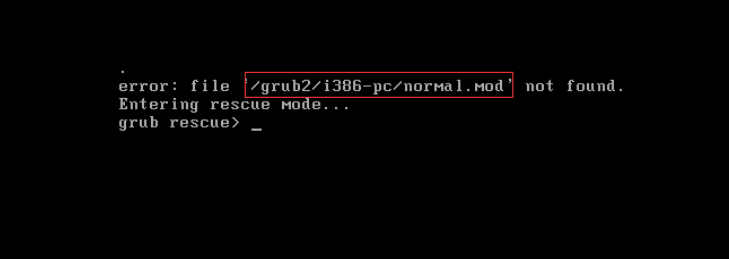
4.单用户模式
忘记root账户密码导致无法登陆系统时,只需要进入emergency mode(单用户模式)更新root账户的密码即可。
单用户模式可以用来修改文件系统损坏、还原配置文件、移动用户数据等。
1.修改密码 CentOS6
1)重启系统,到grub菜单界面
回车返回内核菜单
进入后就可以重新设置密码了
密码设置好重启就OK了
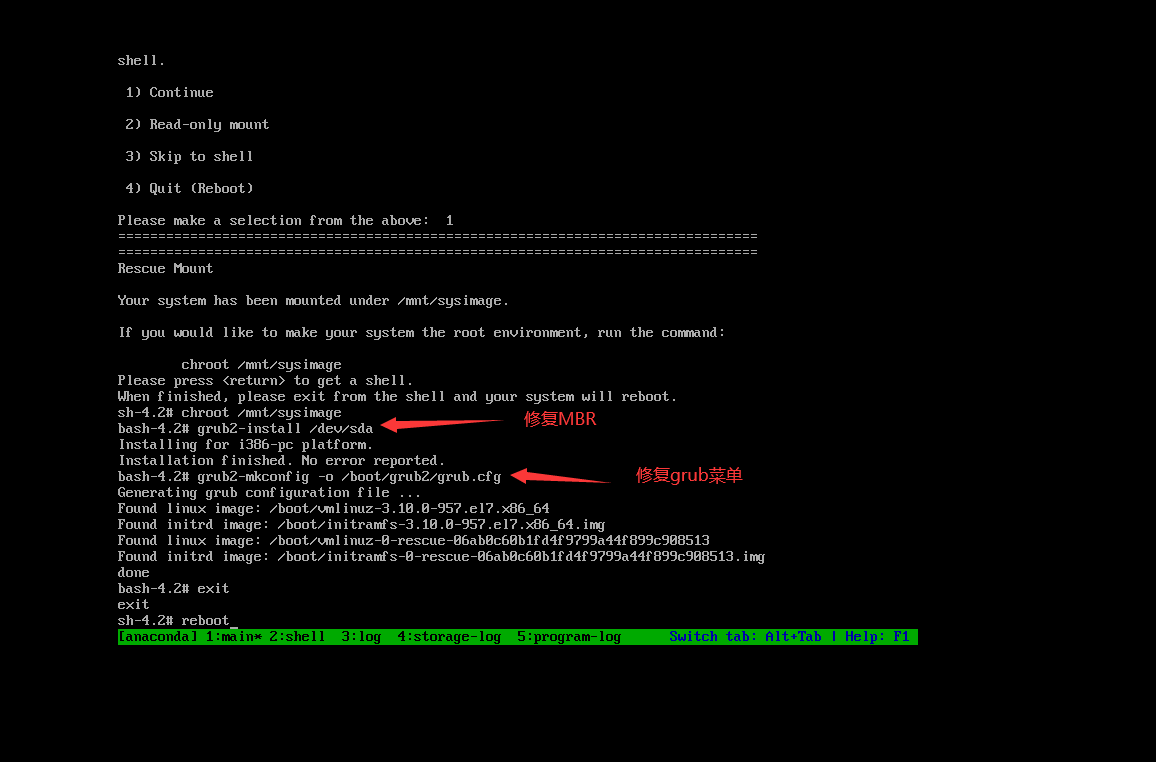
CentOs7
1.重启系统
2.进入grub2菜单
1 2 3 enforcing=0 init=/bin/bash enforcing=0 关闭selinux(临时的),进入单用户后配置文件里关闭selinux,否则重新开机后密码就不生效了
不挂载方式
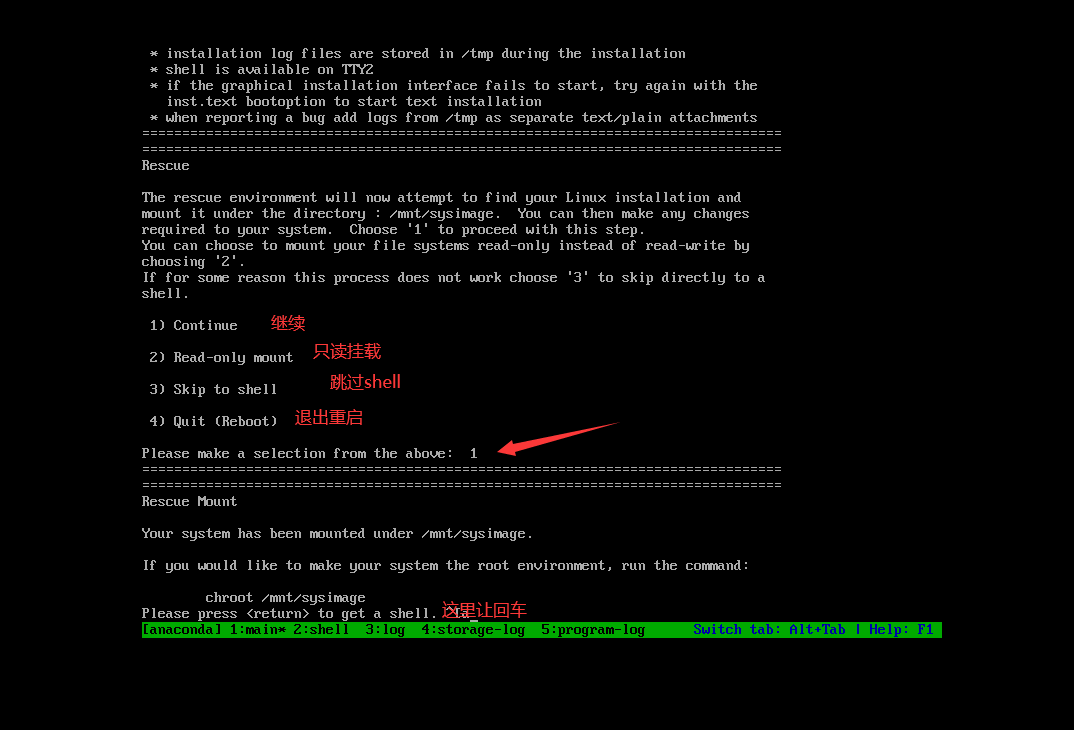
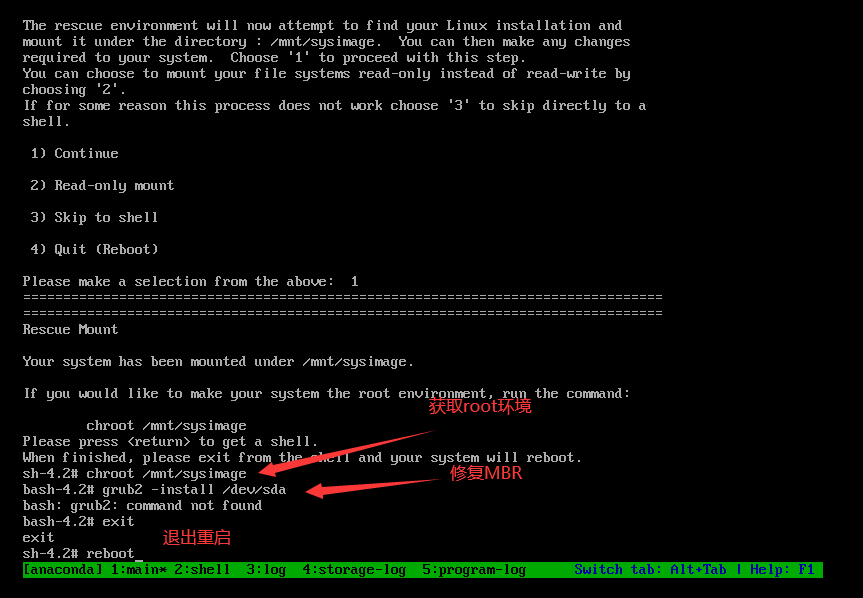
3.进入单用户模式
1 2 3 4 5 6 mount -o rw,remount / passwd root exec /sbin/init
2.修改运行级别 如果centos7被设置为运行级别6,导致无限重启怎么解决?
1 2 3 4 5 [root@yum_repo ~]# systemctl get-default multi-user.target [root@yum_repo ~]# systemctl set-default reboot.target
解决办法
1.进入编辑模式
2.#在linux16行的末尾输入,然后按下 Ctrl+X 组合键来运行修改过的内核程序
exit退出,reboot重启
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 mount -o rw,remount /sysroot chroot /sysrootpasswd root systemctl set-default multi-user.target exit reboot [root@yum_repo ~]# setenforce 0 [root@yum_repo ~]# vi /etc/sysconfig/selinux SELINUX=disabled 1)enforcing=0 init=/bin/bash // 修改密码 2)rd.break // 修改运行级别
【2】文件和目录管理 1.目录结构 1 2 3 几乎所有的计算机操作系统都是使用目录结构组织文件。具体来说就是在一个目录中存放子目录和文件,而在子目录中又会进一步存放子目录和文件,以此类推形成一个树状的文件结构,由于其结构很像一棵树的分支,所以该结构又被称为目录树。 windows:一多根的方式组织文件C:\ D:\ Linux:以单根的方式组织文件 /
目录层次的标准FHS
1 2 3 4 5 FHS全称(File system Hierarchy Standard),中文意思是目录层次标准,是Linux的目录规范标准。 FHS定义了两次规范: 1 .“/”目录下的各个目录应该放什么文件数据。2 .针对/usr 和 /var 这两个目录的子目录来定义。
bin -> usr/bin 这个是usr/bin的快捷方式
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 -rw-r--r--. 1 root root 0 Mar 28 11:29 1.txt lrwxrwxrwx. 1 root root 7 Mar 27 12:07 bin -> usr/bin dr-xr-xr-x. 5 root root 4096 Mar 27 12:11 boot -开头的是文件 l开头的是快捷方式 -> dr开头的是文件夹 bin -> usr/bin sbin -> usr/sbin lib -> usr/lib lib64 -> usr/lib64 boot media mnt opt srv *****重点***** 1)root 2)home 3)run 4)sys 5)tmp 6)usr 7)dev 8)etc 9)proc 10)var
① /dev目录 1 2 3 4 5 6 7 8 /dev/sda /dev/sda1 /dev/sda2 /dev/sdb /dev/random /dev/null /dev/cdrom /dev/pts/{0 1 2 3}
② /etc目录 1 2 3 4 5 /etc/hosts /etc/passwd /etc/sysconfig/network-scripts/ifcfg-网卡名 /etc/hostname /etc/resolv.conf
③ /etc其它目录 *了解 1 2 3 4 /etc/opt/ /etc/X11/ /etc/sgml/ /etc/xml/
④ /proc和/var目录 1 2 3 /proc/m eminfo /proc/ cpuinfo 在Linux中,对应Procfs格式挂载。该目录下文件只能看不能改(包括root)
/var目录
1 2 3 /var/log /messages # 系统日志 /var/log /secure # 系统登录日志 #变量文件——在正常运行的系统中其内容不断变化的文件,如日志,脱机文件和临时电子邮件文件。有时是一个单独的分区。如果不单独分区,有可能会把整个分区充满。如果单独分区,给大给小都不合适。
文件的路径定位
特殊目录’.’ 和’..’
⑤ 其它目录 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 /etc/rc /etc/rc.d ***** /etc/hosts ***** /etc/sysconfig/network ***** /etc/resolv.conf ***** /etc/fstab ***** /etc/inittab ***** /etc/exports ***** /etc/init.d/ ***** /etc/profile ***** /etc/csh.login, /etc/csh.cshrc /etc/issue ***** /etc/motd /etc/mtab /etc/group ***** /etc/passwd ***** /etc/shadow ****** /etc/sudoers ***** /etc/syslog.conf ***** /etc/login.defs /etc/securetty /etc/printca /etc/shells /etc/xinetd.d /etc/opt/ /etc/X11/ /etc/sgml/ /etc/xml/ /etc/skel/ *****
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 /usr/X11R6 /usr/games /usr/doc /usr/include /usr/lib /usr/man /usr/src /usr/bin/ /usr/lib/ /usr/sbin/ /usr/share/ /usr/src/ /usr/X11R6/ /usr/local/
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 /var/log/message ***** /var/spool/cron/root ***** /var/log/secure ***** /var/log/wtmp /var/spool/clientmqueue/ /var/spool/mail/ /var/tmp /var/lib /var/local /var/lock /var/log/ ***** /var/run /var/cache/
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 /proc/meminfo ***** /proc/loadavg ***** /proc/uptime ***** /proc/cpuinfo ***** /proc/cmdline /proc/filesystems /proc/interrupts /proc/ioports /proc/kcore /proc/modules /proc/mounts /proc/swaps /proc/partitions /proc/pci /proc/version /proc/bus/*
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 /dev/hd[a-t] /dev/sd[a-z] /dev/fd[0-7] /dev/md[0-31] /dev/loop[0-7] /dev/ram[0-15] /dev/null /dev/zero /dev/tty[0-63] /dev/ttyS[0-3] /dev/lp[0-3] /dev/console /dev/fb[0-31] /dev/cdrom /dev/modem /dev/pilot /dev/random /dev/urandom
2.查看相关命令 ① cat
选项
作用
-n
显示行号
-T
用来区分文件中是否有制表符
-E
判断文件中内容每一行结束位置
-A
相当于-E -T
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 cat [选项]... [文件]...cat [OPTION]... [FILE]...[root@localhost ~]# cat /etc/passwd [root@localhost ~]# cat 1.txt 2.txt 123 abc [root@localhost ~]# cat 2.txt 1.txt abc 123 OOM: out of memory 内存溢出 OOM killer [root@localhost ~]# cat -n /etc/passwd 1 root:x:0:0:root:/root:/bin/bash 2 bin:x:1:1:bin:/bin:/sbin/nologin 3 daemon:x:2:2:daemon:/sbin:/sbin/nologin 4 adm:x:3:4:adm:/var/adm:/sbin/nologin 5 lp:x:4:7:lp:/var/spool/lpd:/sbin/nologin 6 sync :x:5:0:sync :/sbin:/bin/sync 7 shutdown:x:6:0:shutdown:/sbin:/sbin/shutdown 8 halt:x:7:0:halt:/sbin:/sbin/halt 9 mail:x:8:12:mail:/var/spool/mail:/sbin/nologin 10 operator:x:11:0:operator:/root:/sbin/nologin [root@localhost ~]# cat -T 1.txt abc 123 789 qwe^Iwww^I777 a^I^I^I^I aaaaa bbbb [root@localhost ~]# cat -E 1.txt abc 123 789$ $ qwe www 777 $ aaaa$ $ $ [root@localhost ~]# cat -A 1.txt abc 123 789$ $ qwe^Iwww^I777 $ aaaa$ $ Tab 制表符 回车 换行符 [root@localhost ~]# cat >> suibian.txt <<EOF(不一定是Eof,起到终止作用) 但使龙城free将在 xxx aaa ccc EOF [root@localhost ~]# cat >> gushi.txt <<zls (这里就不一定是Eof) > 1111 > 2222 > 3333 > zls [root@localhost ~]# cat > 1.txt <<EOF #一个 > 是写入新内容并覆盖 > abc > EOF [root@localhost ~]# cat 1.txt abc [root@localhost ~]# cat >> 1.txt <<EOF #两个>>是追加内容不覆盖 > 123 > 456 > EOF [root@localhost ~]# cat 1.txt abc 123 456
② tail & head ==tail==
选项
作用
-n
指定查看多少行 number
-f
follow 跟随,跟踪文件末尾
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 [root@localhost ~]# tail /etc/passwd ftp:x:14:50:FTP User:/var/ftp:/sbin/nologin nobody:x:99:99:Nobody:/:/sbin/nologin systemd-network:x:192:192:systemd Network Management:/:/sbin/nologin dbus:x:81:81:System message bus:/:/sbin/nologin polkitd:x:999:998:User for polkitd:/:/sbin/nologin sshd:x:74:74:Privilege-separated SSH:/var/empty/sshd:/sbin/nologin postfix:x:89:89::/var/spool/postfix:/sbin/nologin zls1:x:1000:1000::/home/zls1:/bin/bash apache:x:48:48:Apache:/usr/share/httpd:/sbin/nologin zls100:x:1001:1001::/home/zls100:/bin/bash [root@localhost ~]# tail -n2 /etc/passwd apache:x:48:48:Apache:/usr/share/httpd:/sbin/nologin zls100:x:1001:1001::/home/zls100:/bin/bash [root@localhost ~]# tail -2 /etc/passwd apache:x:48:48:Apache:/usr/share/httpd:/sbin/nologin zls100:x:1001:1001::/home/zls100:/bin/bash [root@localhost ~]# tail -f 1.txt 可以查看实时更新的日
==head==
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 作用:指定查看多少行 number [root@localhost ~]# head /etc/passwd root:x:0:0:root:/root:/bin/bash bin:x:1:1:bin:/bin:/sbin/nologin daemon:x:2:2:daemon:/sbin:/sbin/nologin adm:x:3:4:adm:/var/adm:/sbin/nologin lp:x:4:7:lp:/var/spool/lpd:/sbin/nologin sync :x:5:0:sync :/sbin:/bin/syncshutdown:x:6:0:shutdown:/sbin:/sbin/shutdown halt:x:7:0:halt:/sbin:/sbin/halt mail:x:8:12:mail:/var/spool/mail:/sbin/nologin operator:x:11:0:operator:/root:/sbin/nologin [root@localhost ~]# head -n3 /etc/passwd root:x:0:0:root:/root:/bin/bash bin:x:1:1:bin:/bin:/sbin/nologin daemon:x:2:2:daemon:/sbin:/sbin/nologin [root@localhost ~]# head -n 3 /etc/passwd root:x:0:0:root:/root:/bin/bash bin:x:1:1:bin:/bin:/sbin/nologin daemon:x:2:2:daemon:/sbin:/sbin/nologin [root@localhost ~]# head -3 /etc/passwd root:x:0:0:root:/root:/bin/bash bin:x:1:1:bin:/bin:/sbin/nologin
③ more & less ==more==
1 [root@db04 ~]# more /etc/services
==less==
1 2 3 [root@db04 ~]# less /etc/services [root@db04 ~]# less -N /etc/services
④ grep
选项
作用
-n
显示行号
-A
After 过滤关键字并打印出后N行
-B
Before 过滤关键字并打印出前N行
-C
Center 过滤关键字并打印出前后N行
-v
取反
-o
只显示关键字内容
-i
忽略大小写
-w
精确匹配,显示匹配的这一行
-c
相当于count,用于统计行数
-r/-R
递归搜索目录及目录下得文件
关键字可以使用的符号
作用
^
以……开头
$
以……结尾 ^$可以表示空行
.
任意一个字符
*
*号前面的单个字符匹配0次或多次
\
正则表达式里面或者意思,grep默认不支持正则表达式,需要用-E
\b
边界符
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 grep [选项]... '关键字' [文件名]... [root@localhost ~]# grep '风景' zls.txt 江山风景美如画, [root@localhost ~]# grep -n 'root' /etc/passwd 1:root:x:0:0:root:/root:/bin/bash 10:operator:x:11:0:operator:/root:/sbin/nologin [root@localhost ~]# cat zls.txt 卧槽 作者:曾老湿 江山风景美如画, 本想吟诗赠天下。 奈何自己没文化, 一句卧槽风好大。 就这么地吧。 谢谢大家。 一二三四五六七, 七六五四三二一。 [root@localhost ~]#grep '一' zls.txt 一句卧槽风好大。 一二三四五六七, 七六五四三二一。 [root@localhost ~]#grep '^一' zls.txtt 一句卧槽风好大。 一二三四五六七, [root@localhost ~]# grep -n '^一' zls.txt 6:一句卧槽风好大。 9:一二三四五六七, [root@localhost ~]# grep 'login$' /etc/passwd [root@localhost ~]# grep 'mail' -A 2 /etc/passwd mail:x:8:12:mail:/var/spool/mail:/sbin/nologin operator:x:11:0:operator:/root:/sbin/nologin games:x:12:100:games:/usr/games:/sbin/nologin [root@localhost ~]# grep -B 2 'mail' /etc/passwd shutdown:x:6:0:shutdown:/sbin:/sbin/shutdown halt:x:7:0:halt:/sbin:/sbin/halt mail:x:8:12:mail:/var/spool/mail:/sbin/nologin [root@localhost ~]# grep -A3 -B2 'mail' /etc/passwd shutdown:x:6:0:shutdown:/sbin:/sbin/shutdown halt:x:7:0:halt:/sbin:/sbin/halt mail:x:8:12:mail:/var/spool/mail:/sbin/nologin operator:x:11:0:operator:/root:/sbin/nologin games:x:12:100:games:/usr/games:/sbin/nologin ftp:x:14:50:FTP User:/var/ftp:/sbin/nologin [root@localhost ~]# grep -C2 'mail' /etc/passwd shutdown:x:6:0:shutdown:/sbin:/sbin/shutdown halt:x:7:0:halt:/sbin:/sbin/halt mail:x:8:12:mail:/var/spool/mail:/sbin/nologin operator:x:11:0:operator:/root:/sbin/nologin games:x:12:100:games:/usr/games:/sbin/nologin
⑤ ls
选项
作用
-l
查看目录下文件的名字和详细信息
-a
查看目录下所有文件包括隐藏文件
-h(一般配合-l使用)
以人类可读的方式查看文件详细信息
-t(一般配合-l使用)
按照文件修改日期排序,最新的在最上面
-r(一般配合-l使用)
reverse翻转(倒叙排序)
-d(一般配合-l使用)
只查看目录本身信息不查看文件
-i(一般配合-l使用)
显示inode号
-S(一般配合-l使用)
依据内容大小将文件排序显示
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 list [root@lb02 ~]# ls anaconda-ks.cfg ip_host.sh ip_host.sh~ -l use a long listing format 使用一个长的列表格式 [root@lb02 ~]# ls -l total 12 -rw-------. 1 root root 1447 Mar 27 12:11 anaconda-ks.cfg -rw-r--r--. 1 root root 377 Mar 27 23:50 ip_host.sh -rw-r--r--. 1 root root 366 Mar 27 23:33 ip_host.sh~ [root@lb02 ~]# ll total 12 -rw-------. 1 root root 1447 Mar 27 12:11 anaconda-ks.cfg -rw-r--r--. 1 root root 377 Mar 27 23:50 ip_host.sh -rw-r--r--. 1 root root 366 Mar 27 23:33 ip_host.sh~ [root@lb02 ~]# ls -l /etc/sysconfig/ total 84 -rw-r--r--. 1 root root 379 Mar 27 12:11 anaconda -rw-r--r--. 1 root root 483 Mar 27 12:10 authconfig drwxr-xr-x. 2 root root 43 Mar 27 12:07 cbq drwxr-xr-x. 2 root root 6 Oct 31 2018 console -a,--all do not ignore entries starting with . [root@lb02 ~]# ls -l -a 或者[root@lb02 ~]# ls -la/ls -al [root@lb02 ~]# ls -l -a total 48 dr-xr-x---. 2 root root 195 Mar 27 23:50 . dr-xr-xr-x. 17 root root 224 Mar 27 12:10 .. -rw-------. 1 root root 1447 Mar 27 12:11 anaconda-ks.cfg [root@lb02 ~]# ls -l /etc/sysconfig/ebtables-config -rw-------. 1 root root 1390 Apr 11 2018 /etc/sysconfig/ebtables-config [root@lb02 ~]# ls -hl /etc/sysconfig/ebtables-config -rw-------. 1 root root 1.4K Apr 11 2018 /etc/sysconfig/ebtables-config [root@lb02 ~]# ls -l //不排序 total 12 -rw-------. 1 root root 1447 Mar 27 12:11 anaconda-ks.cfg -rw-r--r--. 1 root root 377 Mar 27 23:50 ip_host.sh -rw-r--r--. 1 root root 366 Mar 27 23:33 ip_host.sh~ [root@lb02 ~]# ls -lt total 12 -rw-r--r--. 1 root root 377 Mar 27 23:50 ip_host.sh -rw-r--r--. 1 root root 366 Mar 27 23:33 ip_host.sh~ -rw-------. 1 root root 1447 Mar 27 12:11 anaconda-ks.cfg [root@lb02 ~]# ls -ltr total 12 -rw-------. 1 root root 1447 Mar 27 12:11 anaconda-ks.cfg -rw-r--r--. 1 root root 366 Mar 27 23:33 ip_host.sh~ -rw-r--r--. 1 root root 377 Mar 27 23:50 ip_host.sh [root@lb02 ~]# ls -ld /etc/sysconfig drwxr-xr-x. 6 root root 4096 Mar 27 12:11 /etc/sysconfig
⑥ tree
选项
作用
-L
指定层级显示结构
-d
只查看目录不查看文件
-a
显示所有文件和目录包括隐藏文件
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 [root@localhost ~]# tree -bash: tree: command not found [root@localhost ~]# yum install -y tree [root@lb01 ~]# tree /usr/local/ /usr/local/ ├── bin ├── etc │ ├── applications │ ├── info │ └── man │ ├── man1 │ ├── man1x │ ├── man2 │ ├── man2x │ ├── man3 │ ├── man9x │ └── mann └── src 32 directories, 0 files [root@lb01 ~]# tree -L 2 /usr/local/ [root@localhost ~]# tree -L 2 -d /etc/
3.增删改操作 ① cp
选项
作用
-r、-R
递归复制目录(包括目录下的所有内容)
-v
显示复制的详细信息,复制过程
-p
保持文件属性
-a
即保持目录属性,又可以递归拷贝目录
-i
询问 (是否覆盖)
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 copy 复制,拷贝 1.cp [选项]... [-T] 源文件 目标 (备份) 2.cp [选项]... 源文件... 目录 3.cp [选项]... -t 目录 源文件... cp [OPTION]... [-T] SOURCE DEST[root@localhost ~]# cp saomiao.sh 123 [root@localhost ~]# cp saomiao.sh /opt/abc cp [OPTION]... SOURCE... DIRECTORY[root@localhost ~]# cp saomiao.sh /tmp/ [root@localhost ~]# cp saomiao.sh /tmp/2.txt [root@localhost ~]# cp 123 saomiao.sh cheak_student.sh anaconda-ks.cfg /opt/ [root@localhost ~]# cp 123 saomiao.sh cheak_student.sh anaconda-ks.cfg abc(必须是目录,不能是文件) cp : target ‘abc’ is not a directory[root@localhost ~]# cp -r /opt/ /tmp/ 将opt目录下所有文件复制到tmp下,包括opt目录 [root@localhost ~]# cp -r /opt/ /root/xxx [root@localhost ~]# cp -r /opt/* /tmp/ [root@localhost ~]# cp -rv 123 anaconda-ks.cfg /tmp/ ‘123’ -> ‘/tmp/123’ ‘anaconda-ks.cfg’ -> ‘/tmp/anaconda-ks.cfg’ [root@localhost ~]# cp -rp /home/zls1 /tmp/ [root@localhost ~]# cp -a /home/zls1 /tmp/ ---- cp [OPTION]... -t DIRECTORY SOURCE...[root@localhost ~]# cp -t /tmp/ saomiao.sh 1.当复制的目标不存在时,将源文件复制出来并改名为目标名 2.当复制目标存在时,且是一个目录,则直接将文件复制到指定的目录下(名字不变) 3.当复制目标存在时,且是一个普通文件,则提示是否要覆盖,输入y是覆盖,输入n是不覆盖 4.当复制多个文件时,最后一个必须写已存在的目录,否则会报错 5.cp 命令默认情况下无法拷贝目录,必须加-r选项,递归复制目录
② mv 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 -i 询问(是否要覆盖) move 移动,剪切 1.mv [选项]... [-T] 源文件 目标(重命名) 2.mv [选项]... 源文件... 目录 3.mv [选项]... -t 目录 源文件... (反人类) mv [OPTION]... [-T] SOURCE DEST[root@localhost ~]# mv saomiao.sh zls.sh mv [OPTION]... SOURCE... DIRECTORY[root@localhost ~]# mv zls.sh /opt/ [root@localhost ~]# mv nginx.conf 123 mv : overwrite ‘123’? y[root@localhost ~]# mv /tmp/{123,anaconda,ks.cfg,cheak_student.sh,nginx.conf.bak} . [root@localhost ~]# ll total 8 -rw-r--r--. 1 root root 0 Apr 1 19:18 123 -rw-------. 1 root root 1379 Mar 21 20:58 anaconda-ks.cfg -rw-r--r--. 1 root root 392 Aug 11 2022 cheak_student.sh -rw-r--r--. 1 root root 0 Apr 1 19:18 nginx.conf.bak [root@localhost ~]# mv 123 anaconda-ks.cfg cheak_student.sh nginx.conf.bak abc 同cp ,abc不是目录 mv : target ‘abc’ is not a directory1.当移动的目标不存在时,将源文件重命名 2.当移动目标存在时,且是一个目录,则直接将文件剪切到指定的目录下(名字不变) 3.当移动目标存在时,且是一个普通文件,则提示是否要覆盖,输入y是覆盖,输入n是不覆盖 4.当移动多个文件时,最后一个必须写已存在的目录,否则会报错 mv [OPTION]... -t DIRECTORY SOURCE...
③ rm
选项
作用
-i
询问(是否要删除)
-r
递归删除
-f
force 强制删除
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 remove 删除(delete) rm [OPTION]... FILE...[root@localhost ~]# rm 123 [root@localhost ~]# rm -r zls2 [root@localhost ~]# rm -r zls2/* rm : remove regular empty file ‘123’? y[root@localhost ~]# rm -rf zls2/ [root@localhost ~]# rm -fr /tmp/* 1.rm 删除普通文件的命令,默认只能删除普通文件 [root@localhost ~]# rm zls1 rm : cannot remove ‘zls1’: Is a directory2.删除文件,不想询问,rm -f 3.删除目录,不想询问,rm -fr 、 rm -rf 1.在命令前面加\(转义符)[root@lb01 ~]# \rm -r ac 2.使用命令的绝对路径 查看命令的绝对路径在哪which rm /usr/bin/rm 使用绝对路径删除/usr/bin/rm -r ab 就没有提醒是否删除即不走别名
④ touch 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 touch 目标文件touch [OPTION]... FILE...[root@www ~]# touch 1.txt abc/2.txt /tmp/3.txt [root@www ~]# touch /iskshda/1.txt touch : cannot touch ‘/iskshda/1.txt’: No such file or directory[root@www ~]# touch 1.txt 1)当创建的目标文件不存在,则创建一个普通文件 2)当创建的目标文件存在时,则修改该文件的时间 3)当创建的目标是一个目录时,则修改目录的时间
⑤ mkdir
选项
作用
-p
递归创建,如果目录已存在则不创建,如果目录不存在则创建
-v
显示创建的详细信息(创建的过程)
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 make directory mkdir 目标目录[root@lb02 ~]# mkdir /abc /123 /456 每个目录要有空格 [root@lb02 ~]# mkdir -p /abc/123/456 789 789是在当前目录下创建的 [root@lb02 ~]# mkdir a mkdir : cannot create directory ‘a’: File exists[root@lb02 ~]# mkdir -pv a/b/c mkdir : created directory ‘a/b’ 因为a已经存在,若不存在则会有mkdir : created directory ‘a’mkdir : created directory ‘a/b/c’[root@lb02 ~]# mkdir /etc/passwd/123 mkdir : cannot create directory ‘/etc/passwd/123’: Not a directory // 不是一个目录[root@lb01 ~]# mkdir {a..c} [root@lb01 ~]# ls a b c [root@lb01 ~]# mkdir /tmp/{a,b,c,d}在/tmp下创建a,b,c,d四个目录 [root@localhost ~]# mkdir -p 111/{2,3}/abc 分别在111/2和111/3创建abc 目录 /tmp/a /tmp/b /tmp/1 /tmp/2 1.[root@www ~]# mkdir {/tmp/a,/tmp/b,/tmp/1,/tmp/2 2.[root@www ~]# mkdir /tmp/{a,b,1,2}
⑥ tr 替换 1 2 3 4 5 6 7 8 9 10 11 tr '被替换的内容' '替换内容' < 文件名[root@localhost ~]# tr 'name' 'address' < 2.txt addr=10.0.0.100 [root@localhost ~]# tr 'nameqws' 'address' < 2.txt address=10.0.0.100 sed 's/被替换内容/替换内容/g' 文件名 [root@localhost ~]# sed 's///g' 2.txt [root@localhost ~]# sed 's/name/address/g' 2.txt address=10.0.0.100
4.文件处理命令 ① sort
选项
作用
-k
按照指定列进行排序(默认以空格为分隔符)
-t
指定文件的分隔符
-n
以阿拉伯数字的形式进行排序
-r
reverse 倒叙排序
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 语法: sort [选项]... [文件]...[root@localhost ~]# sort 1.txt a:4 b:3 c:2 d:1 e:5 f:11 总结: 1)默认情况下 sort 按照文件每一行的首字母进行排序 2)默认情况下 在sort 眼里分隔符只有空格 3)在sort 命令中,分隔符,必须是一个字符,不能为空 sort -k2 -k4 11.txt
② uniq 去重
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 uniq [选项]... [文件]...前提条件:重复行的内容,必须挨着,否则无法去重 abc 123 abc 123 abc abc 123 123 [root@localhost ~]# cat uniq.txt abc 123 abc 123 [root@localhost ~]# sort uniq.txt |uniq 123 abc [root@localhost ~]# sort uniq.txt|uniq -c 2 123 2 abc
③ cut 截取
选项
作用
-d
指定分隔符
-f
指定区域
-n
指定行
-c
按照字符截取
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 cut OPTION... [FILE]...[root@localhost ~]# cut -d ' ' -f 6 4.txt [root@lb01 ~]# ifconfig ens33|grep -w 'inet' |cut -d ' ' -f 10,13 [root@localhost ~]# cut -c 9-10 4.txt 使用awk命令截取使用示例 [root@lb02 ~]# ip a|awk -F '[ /]' 'NR==9{print $6}' 10.0.0.6 注意: 1)cut 默认没有分隔符,必须指定
④ wc 统计
选项
作用
-l
line 统计行数
-w
word 统计单词数量
-c
char 统计字符数量
1 2 3 4 5 6 7 8 9 10 11 12 13 14 wc [option]... file...[root@localhost ~]# wc /etc/services 11176 61033 670293 /etc/services [root@localhost ~]# wc -l /etc/services 11176 /etc/services [root@localhost ~]# wc -w /etc/services 61033 /etc/services [root@localhost ~]# wc -c /etc/services 670293 /etc/services [root@localhost ~]# ifconfig |wc -w 108 [root@localhost ~]# ip a |wc -w
⑤ wget & curl 下载 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 - O 指定下载路径,也可以给下载的改名 wget 可以用外网下载东西到服务器中 -bash: wget: command not found没有找到wget命令 [root@localhost ~]# yum install -y wget [root@localhost ~]# wget https://dldir1.qq.com/qqfile/qq/QQNT/Linux/QQ_3.2.7_240401_x86_64_01.rpm [root@localhost ~]# yum install -y lrzsz [root@localhost ~]# sz w700d1q75cms.jpg [root@localhost ~]# rz curl -o 链接 可以指定下载路径,还有可以给下载的文件改名
6.文件属性
文件字符类型
文件类型
-
file 普通文件
d
directory 目录
c
char 字符设备
b
block 块设备
l
link 链接文件
s
socket 安全 (套接字)文件
p
pipe 管道文件
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 硬链接数 所属用户 所属用户组 文件大小 时间 文件名 - rw-r--r--. 1 root root 289 Apr 7 16:40 11.txt d rwxr-xr-x. 4 root root 41 Apr 3 18:04 zls [root@localhost ~]# ll /dev/null -d crw-rw-rw-. 1 root root 1, 3 Apr 7 16:21 /dev/null [root@localhost ~]# ll /dev/sda1 brw-rw----. 1 root disk 8, 1 Apr 7 16:21 /dev/sda1 [root@localhost ~]# ll /run/systemd/initctl/fifo prw-------. 1 root root 0 Apr 7 16:21 /run/systemd/initctl/fifo [root@localhost ~]# ll /dev/log srw-rw-rw-. 1 root root 0 Apr 7 16:21 /dev/log [root@localhost ~]# ll -d zls/ drwxr-xr-x. 4 root root 41 Apr 3 18:04 zls/ [root@localhost ~]# ll -rw-r--r--. 1 root root 289 Apr 7 16:40 11.txt
① 查看文件类型 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 [root@localhost ~]# ll *.jpg -rw-r--r--. 1 root root 20735 Mar 13 09:08 w700d1q75cms.jpg -rw-r--r--. 1 root root 4 Apr 7 19:50 zls.jpg [root@localhost ~]# file w700d1q75cms.jpg w700d1q75cms.jpg: JPEG image data, EXIF standard [root@localhost ~]# file zls.jpg zls.jpg: empty [root@localhost ~]# echo 111 > zls.jpg [root@localhost ~]# file zls.jpg zls.jpg: ASCII text [root@localhost ~]# file /dev/null /dev/null: character special [root@localhost ~]# file /dev/sda1 /dev/sda1: block special [root@localhost ~]# file /run/systemd/initctl/fifo /run/systemd/initctl/fifo: fifo (named pipe) [root@localhost ~]# file /dev/log /dev/log: socket [root@localhost ~]# file /root/zls /root/zls: directory
② 系统链接文件 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 文件有文件名和数据,在Linux上被分成两个部分:用户数据(user data)与元数据(metadata) 用户数据:文件数据块(data block),数据块是记录文件真实内容的地方,我们将其称为#Block 元数据:文件的附加属性,例如:文件大小,创建时间,属组,属主等,我们称其为#Inode 在Linux中,inode是文件元数据的一部分,但其并不包含文件名,inode号即索引节点号 文件名仅是为了方便人们的记忆和使用,系统或者程序通过inode号寻找正确的文件数据块。 在Linux中,inode(索引节点)是文件系统中的一个数据结构,用于存储文件或目录的元数据信息,包括文件类型、权限、所有者、大小、数据块的位置等。它通过一个唯一的标识符来标识文件或目录,并且在文件系统中具有固定的位置。简而言之,inode是文件系统中用于描述文件或目录属性的数据结构。 cat 1.txtaaa -rw-r--r--. 1 root root 583919 Oct 29 02:33 1.txt >>==元数据inode aaa 真实数据 Block
③ 文件读取流程
④ block介绍
1 2 3 4 5 6 7 block默认大小为4k 一部分存储元数据,存储元数据的部分叫做inode,每个文件都有一个自己的inode号,这个inode号可以理解为文件存储在磁盘上的房间号 一部分存储真实数据,存储真实数据的部分叫做block,一个block默认是4k
⑤ 软链接 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 软链接 ==> 符号链接 soft_link symbolic link ln -s 源文件(要给谁创建快捷方式) 目标文件(快捷方式的位置)[root@localhost ~]# ll -i zls111 1.txt 16803484 -rw-r--r--. 1 root root 279 Apr 7 17:55 1.txt 16799371 lrwxrwxrwx. 1 root root 11 Apr 7 22:34 zls111 -> /root/1.txt [root@localhost ~]# ln -s /root/1.txt /opt 总结: 1)创建软链接时,直接接一个已存在的目录,以源文件名字来命名新的文件名创建到指定目录下 2)创建软链接时,指定一个目录下的文件,如果该文件不存在,则创建软链接并改名 2)创建软链接时,指定一个目录下的文件,如果该文件存在,则报错,无法创建 [root@localhost ~]# ln -s /root/1.txt /tmp/1.txt ln : failed to create symbolic link ‘/tmp/1.txt’: File exists
⑥ 硬链接 若一个 inode 号对应多个文件名,则称这些文件为硬链接。换句话说,硬链接就是同一个文件使用了多 个别名,如下图所示 hard link 就是file的一个别名,他们有共同的 inode
1 2 3 4 5 6 7 8 9 10 11 ln 源文件(要给谁创建硬链接) 目标文件(硬链接的位置)[root@localhost ~]# ll -i total 24 16797812 lrwxrwxrwx. 1 root root 11 Apr 7 23:35 123 -> /root/1.txt 16797823 -rw-r--r--. 6 root root 4 Apr 7 23:37 1.txt 16797823 -rw-r--r--. 6 root root 4 Apr 7 23:37 abc 16797823 -rw-r--r--. 6 root root 4 Apr 7 23:37 abc1 16797823 -rw-r--r--. 6 root root 4 Apr 7 23:37 abc2 16797823 -rw-r--r--. 6 root root 4 Apr 7 23:37 abc3 16797823 -rw-r--r--. 6 root root 4 Apr 7 23:37 abc4
⑦ 软硬链接区别
区别
硬链接
软链接
命令
ln
ln -s
inode
和源文件inode号相同
和源文件inode号不同
源文件
删除源文件不影响链接文件
删除源文件影响链接文件
跨分区创建
不能
可以
目录创建
不能
可以
文件类型
普通文件
l 链接文件
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 [root@localhost ~]# df Filesystem 1K-blocks Used Available Use% Mounted on /dev/sda3 8913920 1609880 7304040 19% / devtmpfs 487048 0 487048 0% /dev tmpfs 497948 0 497948 0% /dev/shm tmpfs 497948 7748 490200 2% /run tmpfs 497948 0 497948 0% /sys/fs/cgroup /dev/sda1 508580 122216 386364 25% /boot tmpfs 99592 0 99592 0% /run/user/0 [root@localhost ~]# df -h Filesystem Size Used Avail Use% Mounted on /dev/sda3 8.6G 1.6G 7.0G 19% / devtmpfs 476M 0 476M 0% /dev tmpfs 487M 0 487M 0% /dev/shm tmpfs 487M 7.6M 479M 2% /run tmpfs 487M 0 487M 0% /sys/fs/cgroup /dev/sda1 497M 120M 378M 25% /boot tmpfs 98M 0 98M 0% /run/user/0 [root@localhost ~]# df -i Filesystem Inodes IUsed IFree IUse% Mounted on /dev/sda3 4462080 34791 4427289 1% / devtmpfs 121762 380 121382 1% /dev tmpfs 124487 1 124486 1% /dev/shm tmpfs 124487 699 123788 1% /run tmpfs 124487 16 124471 1% /sys/fs/cgroup /dev/sda1 256000 326 255674 1% /boot tmpfs 124487 1 124486 1% /run/user/0 [root@localhost ~]# df -ih Filesystem Inodes IUsed IFree IUse% Mounted on /dev/sda3 4.3M 34K 4.3M 1% / devtmpfs 119K 380 119K 1% /dev tmpfs 122K 1 122K 1% /dev/shm tmpfs 122K 699 121K 1% /run tmpfs 122K 16 122K 1% /sys/fs/cgroup /dev/sda1 250K 326 250K 1% /boot tmpfs 122K 1 122K 1% /run/user/0
1 2 CentOS 6:默认使用的是ext4的文件系统13。 CentOS 7:默认使用的是xfs(eXtended File System)文件系统类型
当前磁盘空间还剩余500G,但是就无法往里面写入数据,报错,磁盘空间满了。
1 2 1.inode号储存磁盘空间不足 2.block储存用户真实数据磁盘空间不足
3.vim编辑器 1 2 3 4 vi 和 vim 命令是linux中强大的文本编辑器, 由于Linux系统一切皆文件,而配置一个服务就是在修改其 配置文件的参数。 vim 编辑器是运维工程师必须掌握的一个工具, 没有它很多工作都无法完成。 vim 其实是 vi 的升级版
vim三种工作模式
1 Vim编辑器中设置了三种模式: 命令模式、编辑模式、末行模式,每种模式分别又支持多种不同的命令快捷键,大大提高了工作效率,而且用户在习惯之后也会觉得相当顺手。要想高效率地操作文本,就必须先搞清这三种模式的操作区别以及模式之间的切换方法。
1.命令模式 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 Shift + g |G //将光标跳转到文件最后一行 gg //将光标跳转到文件的第一行 Ngg //将光标跳转到指定行(N为阿拉伯数字) Shift +4 |$ //将光标跳转到当前所在行的行末 Shift +6 |^ |0 // 将光标跳转到当前所在行的行首 yy //复制光标所在行的整行内容 p(小写p) //将复制的内容粘贴到光标所在行的下一行 P(大写P) //将复制的内容粘贴到光标所在行的上一行 Nyy | yNy //将光标所在行整行内容及下面N-1行内容复制(N为阿拉伯数字) dd // 将光标所在行一整行内容,剪切(删除)Ndd | dNd //将光标所在行及下面N-1行内容剪切(N为阿拉伯数字) Shift + d|D // 将光标所在字符及后面整行内容剪切(删除) x // 删除当前光标所在字符 Shift +x|X //将光标所在当前字符的前一个字符删除 d+shift +g|dG //将光标所在行及后面所有行内容删除 U // 撤销上一次操作 Ctrl + r //恢复上一次撤销的操作 r // 替换光标当前所在的一个字符 Shift +r |R //从光标所在字符开始进行替换直到按ESC结束 Ctrl + b // 向前翻页 Ctrl + f // 向后翻页
2.编辑模式 1 2 3 4 5 6 7 8 9 10 11 12 13 -- INSERT -- 像正常的Windows文本编辑器一样,可以随意写入内容 i // 在光标所在位置进入编辑模式(输入内容在光标之前) I // 将光标跳转到光标所在行的行首并进入编辑模式(输入内容在光标之前) a // 将光标跳转到光标所在字符的后一个字符并进入编辑模式(输入内容在光标之前) A // 将光标跳转到光标所在行的行末并进入编辑模式(输入内容在光标之前) s // 将光标所在字符删除并进入编辑模式(输入内容在光标之前) S // 将光标所在行的整行内容删除并进入编辑模式 o // 将光标移动到当前所在行的下一行并进入编辑模式 O // 将光标移动到光标所在行的上一行并进入编辑模式 ESC
3.末行模式 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 显示行号、搜索、替换、保存、退出 ... 1)在命令模式下,输入冒号 2)在命令模式下,输入/ w:write写入(保存 q:quit退出 :w // 只保存但是不退出 :q // 退出但不保存 (没有改内容) :wq // 保存退出 快捷键 Shift + zz | ZZ :x // 保存退出 和:wq相等 :q! // 强制退出 :w! // 强制保存 :wq! // 强制保存并退出 :qw // 错误写法,先退出后保存 E37: No write since last change (add ! to override) // 文件写入内容,没有保存,无法直接退出,除非强制退出 E45: 'readonly' option is set (add ! to override) // 只读文件,无法保存退出,只有root用户可以强制保存退出 E212: Unable to open and write files // 文件无法写入 E212: Can't open file for writing // 文件无法写入,出现原因:1.没有写入权限2.文件写入到一个不存在的目录中
==末行模式—-搜索==
1 2 3 /想要搜索的内容 n:下翻,查找下一个 N:上翻,查找上一个
==末行模式—-替换==
1 2 3 4 :%s#要被替换的内容#替换的内容#g %:所有行 s:search 搜索 g:全局替换
==末行模式—-光标跳转及命令==
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 :set number 简写 :set nu :set nonumber 简写 :set nonu :N (N为阿拉伯数字) :set ic :set noic :set ai :set noai :set list :set nolist set fenc=utf-8set fencs=utf-8,usc-bom,euc-jp,gb18030,gbk,gb2312,cp936set numberset autoindentset smartindentset tabstop=4set shiftwidth=4set rulerset incsearchset showmatchset matchtime=10set ignorecaseset cursorlineset t_Co=256set ?fenc=utf-8?set ?fencs=utf-8,usc-bom,euc-jp,gb18030,gbk,gb2312,cp936set numberset autoindent set smartindent set tabstop=4set shiftwidth=4set rulerset incsearch set showmatch set matchtime=10 set ignorecase set cursorline set t_Co=256
4.视图模式 1 2 3 4 5 6 7 8 块视图模式 -- VISUAL BLOCK -- Ctrl + v 1)Ctrl + v 进入块视图模式 2)按键盘的上下左右,选中想要的内容 3)如果是在行前加入内容,Shift + i 4)如果是在行后加入内容,Shift + a 5)输入想要的内容后,返回命令模式(ESC) 行视图模式 -- VISUAL LINE -- Shit + v
5.vim扩展知识 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 [root@localhost ~]# vim +N 1.txt // N为阿拉伯数字 [root@localhost ~]# vim +3 1.txt [root@localhost ~]# vimdiff 1.txt 2.txt [root@localhost ~]# diff 1.txt 3.txt 3,6c3,6 < http://pxost.baidu.com/index.html < http://mp3.baiadu.com/index.html < http://www.baidu.com/3.html < http://post.baidxu.com/2.html --- > http:aaaaa//pxost.baidu.com/index.html > http://mp3xxx.baiadu.com/index.html > http://www.baxxidu.com/3.html > http://post.baixxdxu.com/2.html [root@localhost ~]# vim -o 1.txt 2.txt // 水平拆分 [root@localhost ~]# vim -O 1.txt 2.txt // 垂直拆分
6.vim写入流程
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 当我们在使用vim编辑文件时 1)首先会在源文件目录下生成一个.swp的临时文件 2)如果vim非正常退出的情况下,该临时文件一直存在 3)下一次编辑则会提示 [O]pen Read-Only, (E)dit anyway, (R)ecover, (Q)uit, (A)bort: 只读模式打开 继续编辑 覆盖 退出 解决方案: 1)查看modified状态 如果是yes ,则需要覆盖源文件 - vim -r /etc/sysconfig/network-scripts/ifcfg-ens33 - vim /etc/sysconfig/network-scripts/ifcfg-ens3 (R)ecover 按 r 2)删除.swp临时文件即可 rm -f /etc/sysconfig/network-scripts/.ifcfg-ens33.swp1)查看modified状态 如果是no,则需要覆盖源文件 (Q)uit 按q退出 2)直接删除.swp临时文件 rm -f /etc/sysconfig/network-scripts/.ifcfg-ens33.swp
4. find命令 1 2 3 4 5 6 7 8 1.忘了某个文件所在的位置,可以通过find来查找。 2.可以查找某个目录下,所有小于1k的文件。 3.可以查找某个目录下,7天之前创建的文件。 4.可以查找某目录下所有以.sh结尾的脚本。 它可以根据不同的条件来进行查找文件:例如权限、拥有者、修改日期/时间、文件大小等等。 同时find命令是Linux下必须掌握的。 [root@lb01 code]# find /code/ -size -4k ! -type d -delete
命令
路径
选项
表达式
动作
find
[path….]
[options…]
[expression]
[action]
逻辑运算符
作用
-a
且 &&
-o
或 \
\
!
非
find的选项
选项
作用
-name
根据文件名查找
-type
根据文件类型查找
-size
根据文件大小找
-time
根据文件的时间找
-user
查找指定用户
-perm
根据文件权限找
-maxdepth
根据句深度查找
-empty
查找空文件(和-type d配合可以指定空目录)
1.根据文件名查找 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 -name [root@localhost ~]# find /etc -name '*ens33*' 加上*是模糊查找 [root@localhost ~]# find /etc -name '*.conf' [root@localhost ~]# find /etc/ -name '*.conf' && find /etc/ -name '*.sh' [root@localhost ~]# find /etc/ -name '*.conf' ;find /etc/ -name '*.sh' [root@localhost ~]# find /etc/ -name '*.conf' -o -name '*.sh' [root@localhost ~]# find /etc/ ! -name '*.conf' [root@localhost ~]# find /etc/ -name 'ifcfg-ens33' [root@localhost ~]# find ./ -iname '*zls*'
2.根据文件类型查找 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 -type 普通文件:f 目录: d 软链接文件:l 套接字文件:s 字符设备文件:c 块设备文件:b 管道文件:p //f 文件 [root@zls ~]# find /dev -type f //d 目录 [root@zls ~]# find /dev -type d //l 链接 [root@zls ~]# find /dev -type l //b 块设备 [root@zls ~]# find /dev -type b //c 字符设备 [root@zls ~]# find /dev -type c //s 套接字 [root@zls ~]# find /dev -type s //p 管道文件 [root@zls ~]# find /dev -type p [root@localhost ~]# find /etc -name '*conf*' -type d [root@localhost ~]# find /etc -name '*conf*' -type d -ls
3.根据文件大小查找 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 -size +:大于 -:小于 [root@localhost ~]# find /tmp -size -4k [root@localhost ~]# find /tmp -size +4k [root@localhost ~]# find /tmp -size 4k [root@localhost ~]# find /code -size -4k -delete [root@localhost ~]# find /code -size -4k ! -type d -delete
4.根据文件的时间查找 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 [root@localhost ~]# stat 1.txt File: ‘1.txt’ Size: 4 Blocks: 8 IO Block: 4096 regular file Device: 803h/2051d Inode: 16797763 Links: 1 Access: (0644/-rw-r--r--) Uid: ( 0/ root) Gid: ( 0/ root) Context: unconfined_u:object_r:admin_home_t:s0 Access: 2024-04-17 19:25:18.951724354 +0800 Modify: 2024-04-17 19:25:18.951724354 +0800 Change: 2024-04-17 19:25:18.951724354 +0800 -mtime:Modify 修改时间 -atime:Access 访问时间 -ctime:Change 时间戳修改时间 +:查找N天之前的(不包含今天) -:查找N天之内的(包含今天) N:查找往前数第N天的(不包含今天) (-mtime后只有数字的) -mtime 7 [root@localhost find]# find /root/find/ -mtime 7 [root@localhost find]# find /root/find/ -mtime +7 [root@localhost find]# find /root/find/ -mtime -7 [root@localhost find]# find /root/find/ ! -mtime -7 -delete
5.根据用户查找 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 -user:查找指定用户 -group:查找指定用户组 -nouser:查找没有用户的文件 -nogroup:查找没有用户组的文件 [root@localhost ~]# find /root/ -user root -group adm -ls [root@localhost ~]# find /root/ \( -group adm -o -user zls \) -ls 16797763 4 -rw-r--r-- 1 zls root 4 Apr 17 2024 /root/1.txt 16797778 4 -rw-r--r-- 1 zls root 4 Apr 16 2024 /root/2.txt 16797816 4 -rw-r--r-- 1 root adm 4 Apr 17 2024 /root/zls.txt 16851189 4 -rw-r--r-- 1 root adm 4 Apr 16 2024 /root/zls1.txt 16851191 4 -rw-r--r-- 1 root adm 4 Apr 16 2024 /root/zls2.txt 16797780 4 -rw-r--r-- 1 root adm 4 Apr 16 2024 /root/zls3.txt 16797813 4 -rw-r--r-- 1 root adm 4 Apr 16 2024 /root/zls4.txt [root@localhost ~]# find /root/ \( -user zls -o -group adm \) -rw-r--r--. 1 zls root 4 Apr 17 2024 /root/1.txt -rw-r--r--. 1 zls root 4 Apr 16 2024 /root/2.txt -rw-r--r--. 1 root adm 4 Apr 16 2024 /root/zls1.txt -rw-r--r--. 1 root adm 4 Apr 16 2024 /root/zls2.txt -rw-r--r--. 1 root adm 4 Apr 16 2024 /root/zls3.txt -rw-r--r--. 1 root adm 4 Apr 16 2024 /root/zls4.txt -rw-r--r--. 1 root adm 4 Apr 17 2024 /root/zls.txt [root@localhost opt]# find /opt/ -nouser -o -nogroup
6.根据文件权限查找 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 perm [root@localhost opt]# find /opt/ -perm 644 -ls 16851186 0 -rw-r--r-- 1 1000 oldboyedu 0 Apr 15 2024 /opt/sbit/1.txt 16851188 0 -rw-r--r-- 1 oldboy oldboyedu 0 Apr 15 2024 /opt/sbit/2.txt 8393463 0 -rw-r--r-- 1 1002 root 0 Mar 30 00:19 /opt/1.txt 8393464 0 -rw-r--r-- 1 root 1000 0 Mar 30 00:19 /opt/2.txt [root@localhost opt]# find /opt/ -perm -622 -ls 16851181 0 drwxrwxrwt 2 root root 32 Apr 15 2024 /opt/sbit [root@zls ~]# find /home -perm /622 8405111 0 drwxr-xr-x 4 root root 77 Mar 30 00:19 /opt/ 16777 0 drwxr-sr-x 2 1000 root 19 Apr 15 2024 /opt/test 16779 0 -rw-rw-r-- 1 1000 root 0 Apr 15 2024 /opt/test/1.txt 16851181 0 drwxrwxrwt 2 root root 32 Apr 15 2024 /opt/sbit 16851186 0 -rw-r--r-- 1 1000 oldboyedu 0 Apr 15 2024 /opt/sbit/1.txt 16851188 0 -rw-r--r-- 1 oldboy oldboyedu 0 Apr 15 2024 /opt/sbit/2.txt 8393448 12 -rw------- 1 root root 9567 Apr 16 2024 /opt/.bash_history 8393463 0 -rw-r--r-- 1 1002 root 0 Mar 30 00:19 /opt/1.txt
7.根据深度查找 1 [root@localhost ~]# find /etc/ -maxdepth 1 -type d
8.动作
动作
作用
-print
打印结果(find 默认就打印结果)
-ls
查看文件详细信息(如果有逻辑运算符,就只查看逻辑运算符后面文件详细信息,除非 使用小括号整体括起来)
- delete
删除查找到的文件(如果有逻辑运算符,就只查看逻辑运算符后面文件详细信息,除非 使用小括号整体括起来)
-ok
执行后面的shell命令(会询问)(如果有逻辑运算符,就只查看逻辑运算符后面文件详 细信息,除非使用小括号整体括起来)
-exec
执行后面的shell命令(不询问)(如果有逻辑运算符,就只查看逻辑运算符后面文件详 细信息,除非使用小括号整体括起来)
1 2 3 4 5 6 7 [root@localhost ~]# find /opt/ -type f -o -name '*st' -exec rm -fr {} \; [root@localhost ~]# find /opt/ -type f -o -name '*st' -ok rm -fr {} \; [root@localhost ~]# find /opt/ -type f -o -name '*st' |xargs rm -fr [root@localhost ~]# find /root/ -type f|xargs cp -t /tmp/ [root@localhost ~]# find /root/ -type d|xargs -I {} cp -r {} /opt/
【3】用户管理 1.用户管理信息 1 2 3 4 1)系统上的每一个进程(运行的程序)都需要特定的用户运行 2)每一个文件都有特定的用户拥有,所以访问一个文件或目录受到用户的限制 3)进程能够以何种方式访问某一个文件或目录, 与进程所关联的用户有关
① 用户查看命令 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 id [option] [user]id [选项] [用户名][root@localhost ~]# id uid=0(root) gid=0(root) groups =0(root) uid:user id 号 gid:group id 号 groups :组名[root@localhost ~]# id -u root 0 [root@localhost ~]# id -g root 0 系统只认uid,用户名是给运维人员看的 在Linux系统中,uid为0的用户才是超级用户 root tty1 2024-04-09 14:54 root pts/0 2024-04-09 11:09 (10.0.0.1) root pts/1 2024-04-09 11:33 (10.0.0.1) tty 代表的是服务器终端登录pts代表的是远程链接工具登录 [root@localhost ~]# whoami root [root@localhost ~]# cat /etc/passwd
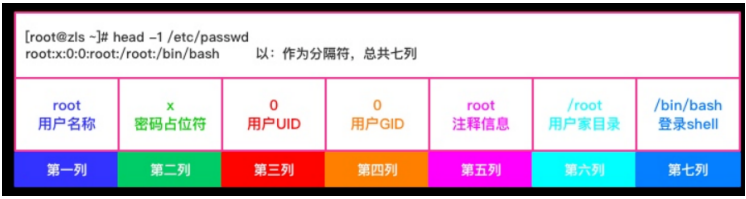
② /etc/passwd
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 [root@lb02 ~]# cat /etc/passwd root:x:0:0:root:/root:/bin/bash bin:x:1:1:bin:/bin:/sbin/nologin daemon:x:2:2:daemon:/sbin:/sbin/nologin adm:x:3:4:adm:/var/adm:/sbin/nologin lp:x:4:7:lp:/var/spool/lpd:/sbin/nologin sync :x:5:0:sync :/sbin:/bin/sync[zls@localhost ~]# useradd wyl -c 'abc' 添加备注 第一列:用户名 第二列:密码占位符 第三列:用户的uid 第四列:用户所在组的gid 第五列:用户的描述信息(备注、注释) 第六列:用户家目录所在路径 第七列:用户登录使用的bash
③ etc/shadow
1 2 3 4 5 6 7 8 9 10 daemon:*:17834:0:99999:7:2:6627567: 第一列: 用户名 第二列: 密码 *和!! 代表没有密码 第三列: 密码修改的时间 从1970年开始计算到上一次变更密码的时间过了多少天 第四列: 密码最少使用天数 0代表无限制 第五列: 密码最长使用天数 99999代表无限制 第六列: 密码到期之前多少天开始提醒 提前7天提醒需要改密码了 第七列: 密码过期后N天强制变更密码 密码过期后2天,强制改密码 第八列: 账户失效时间,从1970年开始计算多少天 第九列: 空 保留列
2.用户管理 ① 创建用户案例 练习创建1000个用户,密码都为1
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 echo '1' |passwd --stdin lgj;分号可以衔接多个命令执行, &&衔接多个命令,但是需要判断前面的命令执行成功后,再执行后面的命令 useradd lgj1;echo "1" | passwd --stdin lgj1 ==>;分号两边分别执行结果 [root@lb01 ~]# seq 1000|awk '{print "useradd lgj"$1";echo 1|passwd --stdin lgj"$1}' |bash vim useradd.sh for i in {1..1000}; do username="lgj$i " useradd $username echo "1" | passwd --stdin $username done 运行sh文件 sh useradd.sh > /dev/null
② 用户约定和规范 ==Linux里用户规范==
centOS7
centOS7
用户UID
作用
用户UID
作用
0
系统管理员(超级用户)
0
系统管理员(超级用户)
1-200
系统用户,由系统分配给进程使用
1-500
系统用户,由系统分配给进程使用运行服务,不需要登录系统
201-999
系统用户,运行服务,不需要登录系统
500+
常规的普通用户
1000+
常规的普通用户
/ /
③ 修改密码 chage ==了解==
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 bin:*:17834:0:99999:7:10:: -d //设置最近一次更改密码时间, 0下次登陆系统强制修改密码 // /etc/shadow 第三列 -m //设置用户两次改变密码之间使用"最小天数" // /etc/shadow 第四列 -M //设置用户两次改变密码之间使用"最大天数" // /etc/shadow 第五列 -W //设置密码更改警告时间 将过期警告天数设为“警告天数” // /etc/shadow 第六列 -I //设置密码过期天数后, 密码为失效状态 // /etc/shadow 第七列 -E //设置用户过期时间, 账户失效后无法登陆 // /etc/shadow 第八列 -l //显示用户信息 [root@lgj ~]# chage -l lgj Last password change : Sep 01, 2014 //最近一次更改密码时间 Password expires : Sep 16, 2014 //密码过期时间 Password inactive : Sep 21, 2014 //密码失效时间 Account expires : Aug 31, 2015 //用户失效时间 Minimum number of days between password change : 2 //密码最短使用时间 Maximum number of days between password change : 15 //密码最长使用时间 Number of days of warning before password expires : 7 //密码过期前警告天数
④ 创建用户(增)
选项
作用
-u
指定uid
-g
指定gid(必须指定一个已存在的组)
-c
指定用户的备注(注释)
-d
指定用户的家目录
-M
不创建家目录
-s
指定用户登录的shell
-G
指定附加组
-r
创建一个用户uid在200 - 999之间
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 使用useradd创建用户将影响到四个文件 /etc/passwd 存放用户名等信息 /etc/shadow 存放密码等信息 /etc/group 存放组信息 /etc/gshadow 存放组密码信息 如果手动创建用户不使用命令,需要分别在1./etc/passwd 2./etc/shadow 3./etc/group 4./etc/gshadow创建用户名组等信息,5.创建用户名的家目录6.拷贝环境变量文件cp /etc/skel/.bash* /home/abc111/ useradd [选项]... 用户名 创建用户名是lgj2 uid1004 用户组1001 备注-c是高杰大大 [root@lb01 ~]# useradd -u 1004 -g 1001 -c 高杰大大 lgj2 -d创建用户lgj6并指定家目录(如果指定的家目录已经存在,如指定aaa(存在)为家目录,会报错目录家目录已经存在,但是还是会创建有lgj6用户,但是没有环境变量) [root@lb01 ~]# useradd lgj6 -d /root/aaa/lgj666 [root@lb01 ~]# useradd lgj7 -M 不创建家目录 [root@lb01 ~]# useradd lgj7 -G 1001,1005 [root@lb01 ~]# useradd lgj8 -G lgj,lgj5 同样指定的组需要已存在 [root@lb01 ~]# id lgj7 uid=1007(lgj7) gid=1007(lgj7) groups =1007(lgj7),1001(lgj),1005(lgj5)
⑤ 修改用户信息(改)
用户
作用
-u
指定用户的uid
-g
指定用户的gid,更换用户所在的主组(指定的组必须存在)
-c
修改备注信息
-d
修改用户家目录,修改/etc/passwd文件内容
-m
配合-d选项,修改完家目录后,迁移家目录
-s
修改用户登录的shell
-G
修改用户的附加组,会替换原来的附加组
-a
修改用户的附加组,配合-G使用,追加附加组
-L
锁定用户(封号)
-U
解锁用户(解封)
-l
修改用户名
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 usermod [选项]... 用户名 修改用户lgj2的uid为1002,gid为1000,备注信息是你好 [root@lb01 ~]# usermod lgj2 -u 1002 -g 1000 -c 你好 [root@localhost ~]# usermod zls000 -d /home/zls000 家目录下的环境变量不会迁移过去 [root@localhost ~]# usermod zls66 -m -d /opt/zls666 需要配合-m使用 如果lgj2主要组不在lgj2里(通过usermod修改了),那么使用userdel删除用户的时候lgj2用户组不会被删除,会提醒lgj2用户的现在用户组不是lgj2的主要组 [root@lb01 ~]# usermod lgj -G 0 修改lgj的附加组(覆盖原有的) [root@lb01 ~]# usermod lgj -aG 100,110 修改lgj的附加组(追加用户组) [root@lb01 ~]# usermod lgj -s /sbin/nologin [root@lb01 ~]# usermod lgj1 -l lgj2 如果修改完将提醒旧的邮箱lgj1将不属于lgj1用户了,var/spool/mail/
⑥ 删除用户(删) 1 2 3 4 5 6 7 8 9 10 userdel [选项]... 用户名 [root@localhost ~]# userdel abd [root@localhost ~]# userdel -r wyl [root@localhost ~]# userdel -r zls888 userdel: zls888 home directory (/home/zls888) not found
⑦ 用户扩展知识 创建用户时候会以下两个文件作为参照物
/etc/login.defs
/etc/defaults/useradd
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 过滤不需要的空行 [root@localhost ~]# grep -i '^[a-z]' /etc/login.defs [root@localhost ~]# grep -Ev '^$|^#' /etc/login.defs MAIL_DIR /var/spool/mail PASS_MAX_DAYS 99999 PASS_MIN_DAYS 0 PASS_MIN_LEN 5 PASS_WARN_AGE 7 UID_MIN 1000 UID_MAX 60000 SYS_UID_MIN 201 SYS_UID_MAX 999 GID_MIN 1000 GID_MAX 60000 SYS_GID_MIN 201 SYS_GID_MAX 999 CREATE_HOME yes UMASK 077 USERGROUPS_ENAB yes ENCRYPT_METHOD SHA512 [root@localhost ~] cat /etc/default/useradd GROUP=100 HOME=/home INACTIVE=-1 EXPIRE= SHELL=/bin/bash SKEL=/etc/skel CREATE_MAIL_SPOOL=yes
⑧用户密码管理 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 passwd 用户名 [root@localhost ~]# passwd [root@localhost ~]# passwd zls [zls@localhost ~]$ passwd Changing password for user zls. Changing password for zls. (current) UNIX password: 原密码: 新密码: 确认密码: echo '密码' |passwd --stdin 用户名CMDB:资产管理系统 [root@localhost ~]# echo $RANDOM |md5sum |cut -c '1-10' be1e4bbb9b md5:校验文件完整性 md5sum :可以给一个字符串生成一段加密后的字符串[root@localhost ~]# mkpasswd -l 24 -d 3 -c 6 -C 7 -s 8 %t[.xl5&74"LP'inQPr+_PWY
3.用户组管理 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 /etc/group /etc/gshadow [root@localhost ~]# head -1 /etc/group root:x:0:zls444444,zls666 第一列:组名 第二列:组密码占位符 第三列:组GID 第四列:组中的附加成员 [root@localhost ~]# head -1 /etc/gshadow root:::zls444444,zls666 root:$6$q0sHS /5GA2D/ARX$KlEkprHkTddlN9tTej7 /ONeMswVmIFASVnhTQMfwN.ue2hDTmqlqXhiM b6oBz8vDCQ/zBzDU2gS88j3pNoIXO.::zls444444,zls666 第一列:组名 第二列:组密码 第三列:组管理员 第四列:组中的附加成员
组相关命令 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 groupadd [选项] 组名 [root@localhost ~]# groupadd ooo [root@localhost ~]# groupadd ppp -g 666 [root@localhost ~]# groupmod ooo -g 888 [root@localhost ~]# groupmod ooo -n xxx [root@localhost ~]# groupdel xxx [root@localhost ~]# gpasswd ppp Changing the password for group ppp New Password [root@localhost ~]# newgrp 组名
4.用户切换 & 提权 ①用户切换 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 su 切换用户,使用普通用户登录,然后使用su命令切换到root。 优点:简单,方便 缺点:需要知道root密码,不安全,切换到root没有日志审计功能 su - 用户名 -c '命令' ('touch 1.txt' ) 可以不切换用户但是以普通用户执行命令 su - 用户名 su 用户名,会少加载一个profile的全局变量 /etc/profile > /etc/profile.d/1.sh > /root/.bashrc > /etc/bashrc /etc/profile /etc/profile.d/1.sh .bash_profile /root/.bashrc /etc/bashrc 个人配置文件: ~/.bash_profile ~/.bashrc 全局配置文件:/etc/profile /etc/profile.d/*.sh /etc/bashrc
②用户身份提权 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 sudo 提权,当需要使用root权限时,进行提权,而无需切换至root用户。优点:安全,方便 缺点:复杂 [zls@localhost ~]$ sudo mkdir /opt/abc We trust you have received the usual lecture from the local System Administrator. It usually boils down to these three things: [sudo ] password for zls: zls is not in the sudoers file. This incident will be reported. [root@localhost ~]# vim /etc/sudoers 在里面添加lgj用户权限 或者visudo命令添加,例如 root ALL=(ALL) ALL lgj ALL=(ALL) ALL 上面注释的有别名,写上别名就可以设置权限,或者自己写某个命令的目录 root ALL=(ALL) ALL lgj ALL=(ALL) /usr/bin/mkdir(这里也可也把上面某个别名注释去掉,写上别名即可使用那个权限) Cmnd_Alias CREATE = /bin/mkdir,/bin/touch 方法一: [root@localhost ~]# visudo root ALL=(ALL) ALL zls ALL=(ALL) CREATE cls1 ALL=(ALL) NOPASSWD: ALL 方法二:只要给用户加入wheel组中,就有sudo 权限 %wheel ALL=(ALL) ALL %lgj ALL=(ALL) NOPASSWD: ALL [root@localhost ~]# useradd lhq1 -G wheel [lhq2@localhost ~]$ sudo -l
【4】权限管理 1.基本权限
1 2 3 4 5 6 7 8 9 10 User Group Other //用户对资源来说, 有三种角色 User(u): 属主用户(文件所有者) Group(g): 属组用户(包含组成员) Other(o): 其他用户
字母
含义
对应权限
r(read)
读取权限
4
w(write)
写入权限
2
x(execute)
执行权限
1
-(没有权限)
没有权限
0
① 修改权限命令 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 chmod [选项] 权限 文件名[root@localhost ~]# chmod 777 test1.txt [root@localhost ~]# ll test1.txt -rwxrwxrwx. 1 root root 0 Apr 12 17:01 test1.txt [root@localhost ~]# chmod 700 test1.txt [root@localhost ~]# ll test1.txt -rwx------. 1 root root 0 Apr 12 17:01 test1.txt [root@localhost ~]# chmod g+xw test1.txt [root@localhost ~]# chmod +x test1.txt [root@localhost ~]# chmod u=rwx,g=w,o=x test1.txt 不如直接修改数字方式 [root@localhost ~]# chmod 721 test1.txt [root@localhost ~]# chmod -R 222 zls121 [root@localhost ~]# ll -d zls121/ d-w--w--w-. 3 zls121 zls121 139 Apr 12 18:31 zls121/ [root@localhost ~]# ll zls121/ total 0 --w--w--w-. 1 root root 0 Apr 12 18:30 1.txt --w--w--w-. 1 root root 0 Apr 12 18:30 2.txt --w--w--w-. 1 root root 0 Apr 12 18:30 3.txt --w--w--w-. 1 root root 0 Apr 12 18:30 4.txt [root@localhost ~]# ll zls121/zls1/ total 0 --w--w--w-. 1 root root 0 Apr 12 18:31 1.txt
② 权限对文件的影响 1 2 3 4 5 6 7 8 9 10 11 当文件只有r权限时,可以查看内容,不能写入(文件所属用户可以使用vi强制保存),不能执行 当文件只有w权限时,不能查看,只能写入(使用vi会覆盖文件内容,使用echo >>可以追加),不能执行 当文件只有x权限时,不能查看,不能写入,不能执行(都看不了无法执行) 当文件只有rw权限时,可以查看,可以写入,不能执行 当文件只有rx权限时,可以查看,不能写入,可以执行 当文件只有wx权限时,不能看,能写入,不能执行 当文件有rwx权限时,可以查看,可以写入,可以执行
③ 权限对目录的影响 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 [zls@localhost ~]$ ll /opt/ ls : cannot open directory /opt/: Permission denied[zls@localhost ~]$ mkdir /opt/zls mkdir : cannot create directory ‘/opt/zls’: Permission denied[zls@localhost ~]$ ./opt -bash: ./opt: No such file or directory 当目录权限为---时,不能查看,不能进入,不能拷贝,不能移动,不能创建,不能删除 当目录权限为r时,能查看目录下的文件名(看不到文件属性),不能进入,不能拷贝,不能移动,不能创建,不能删除 当目录权限为w时,不能查看,不能进入,不能拷贝,不能移动,不能创建,不能删除 当目录权限为x时,不能查看,能进入,不能拷贝,不能移动,不能创建,不能删除 当目录权限为rw时,能查看目录下的文件名(看不到文件属性),不能进入,不能拷贝,不能移动,不能创建,不能删除 当目录权限为rx时,可以查看,能进入,能拷贝,不能移动,不能创建,不能删除 当目录权限为wx时,不能查看,能进入,能拷贝,能移动,能创建,能删除
2.特殊权限 1 普通用户可以修改自己的密码,在于passwd命令,该命令拥有特殊权限,SetUID,也就是咱们看到的,在属主的权限位的执行权限上是 s.当...普通用户使用passwd命令来更改自己的密码时,实际上是在用passwd命令的所有者,所有者是谁?就是root的身份在执行passwd命令
1 2 3 4 5 6 7 8 9 在 Linux 系统中,有三种特殊权限,分别是 SUID 权限、SGID 权限和 SBIT 权限: 允许用户在执行可执行文件时以文件所有者的身份运行。具有 SUID 权限的文件在执行时将继承文件所有者的权限,而不是执行者自己的权限。这对于需要特定权限才能执行的程序非常有用。 SGID 权限类似于 SUID 权限,但是它是针对群组而不是用户。具有 SGID 权限的文件在执行时将继承文件所属群组的权限,而不是执行者所属群组的权限。 主要用于目录。当目录具有 SBIT 权限时,只有目录所有者、文件所有者和 root 用户才能删除或移动该目录中的文件。这可以防止其他用户意外删除或移动他人的文件
SUID
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 [root@localhost ~]# passwd [root@localhost ~]# which passwd /usr/bin/passwd [root@localhost ~]# ll /etc/shadow ----------. 1 root root 641 Apr 12 19:50 /etc/shadow 文件权限:000 所有用户,没有读取权限,写入权限,执行权限 只能修改自己的密码 [zls@localhost ~]$ ll /usr/bin/passwd -rwsr-xr-x. 1 root root 27832 Jun 10 2014 /usr/bin/passwd suid授权方式 特殊权限——setgid 授权方式 如果在一个文件的属主权限位上,出现s权限,代表,该文件具有set uid权限 set uid(suid)权限作用:让使用该文件的用户,以该文件的属主身份执行原因:普通用户在执行passwd命令时,有个判断,就是该命令后面不能加任何参数
==suid授权方式==
1 2 3 4 5 6 7 8 9 10 11 12 13 14 suid数字权限:4000 chmod 4xxx 文件名[root@localhost ~]# chmod 4644 cheak_student.sh [root@localhost ~]# chmod 4755 /bin/passwd [root@localhost ~]# chmod u+s student.txt s:代表该文件的属主权限位上,本身有x(执行)权限 S:代表该文件的属主权限位上,本身没有x(执行)权限 1.让普通用户对可执行的二进制文件,临时拥有二进制文件的所属权限 2.如果设置的二进制文件没有执行权限,那么suid的权限显示就是S 3.特殊权限suid仅对二进制可执行程序有效,其他文件或目录则无效 注意:suid极其危险,不信可以尝试对vim或者rm 命令进行设定suid
SGID 1 2 3 4 5 6 将目录设置为SGID后,如果在该目录下创建文件,都将与该目录的所属组保持一致 [root@localhost ~]# mkdir /opt/test [root@localhost ~]# chmod g+s /opt/test/ [root@localhost ~]# ll /opt/test/ -d drwxr-sr-x. 2 root root 6 Apr 15 18:40 /opt/test/
==授权方式==
1 2 3 4 5 6 7 8 9 10 11 12 13 14 sgid数字权限:2000 chmod 2xxx 文件名[root@localhost ~]# chmod 2644 dir1 [root@localhost ~]# chmod 2755 dir1 小练习 [root@localhost ~]# chmod g+s dir1 s:代表该文件的属组权限位上,本身有x(执行)权限 S:代表该文件的属组权限位上,本身没有x(执行)权限 1.针对用户组权限位修改,用户创建的目录或文件所属组和该目录的所属组一致。 2.当某个目录设置了sgid后,在该目录中新建的文件不在是创建该文件的默认所属组 3.使用sgid可以使得多个用户之间共享一个目录的所有文件变得简单。
SBIT 1 2 sticky(SI TI KI)粘滞,目前只对目录有效,作用如下: 普通用户对该目录拥有w和x权限,即普通用户可以在此目录中拥有写入权限,如果没有粘滞位,那么普通用户拥有w权限,就可以删除此目录下的所有文件,包括其他用户简历的文件。但是一旦被赋予了粘滞位,除了root可以删除所有文件,普通用户就算有w权限也只能删除自己建立的文件,而不能删除其他用户简历的文件。系统中存在的/tmp目录是经典的粘滞位目录,谁都有写权限,因此安全成问题,常常是木马第一手跳板。
==授权方式==
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 SBIT数字权限:1000 suid=4000 sgid=2000 sbit=1000 r=4 w=2 x=1 -=0 chmod 1xxx 文件名[root@localhost ~]# chmod 1644 dir1 [root@localhost ~]# chmod 1755 dir1 [root@localhost ~]# chmod o+t dir1 t:代表该文件的其他用户权限位上,本身有x(执行)权限 T:代表该文件的其他用户权限位上,本身没有x(执行)权限 1.让多个用户都具有写权限的目录,并让每个用户只能删自己的文件(root除外)。 2.特殊sticky目录表现在others的x位,用小t表示,如果没有执行权限是T 3.一个目录即使它的权限为"777" 如果是设置了粘滞位,除了目录的属主和"root" 用户有权限删除,除此之 外其他用户都不允许删除该目录下的所有文件
chattr权限 1 2 3 4 5 6 7 8 9 10 11 chattr只有root用户可以使用,用来修改文件系统的权限属性,建立凌驾于rwx基础权限之上的授权 lsattr /etc/passwd [root@localhost ~]# chattr +i /etc/passwd chattr命令格式:chattr [+-=][选项] 文件名或目录名 [root@localhost ~]# chattr +a /etc/passwd /etc/shadow /etc/group /etc/gshadow
3.进程掩码umask 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 系统默认umask 为022,那么当我们创建一个目录时,正常情况下目录的权限应该是777,但是umask 表示要减 去的值,所以新目录文件的权限应该是777-022=755。至于文件的权限也依次类推:666-022=644 [root@localhost ~]# umask 0022 但是当umask 出现奇数位时,需要在该位上得到结果后+1 [root@localhost ~]# umask 147 [root@localhost ~]# mkdir zls789 // 630 [root@localhost ~]# touch zls456 // 620 [root@localhost ~]# [root@localhost ~]# cat /etc/profileif [ $UID -gt 199 ] && [ "`/usr/bin/id -gn`" = "`/usr/bin/id -un`" ]; then umask 002else umask 022fi 用户家目录umask 077 [root@lb01 ~]# cat /etc/login.defs stat -c a% 文件 stat 文件
4.文件属主属组修改 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 chown [选项] 属主:属组 文件名[root@localhost ~]# chown zls:zls student.txt [root@localhost ~]# chown root.root student.txt [root@localhost ~]# chown :tls student.txt [root@localhost ~]# chown zls student.txt 一个用户,创建出来的文件,不一定权限属于他的主组,newgrp只要切换过组,在哪个组工作,创建出的文件属组就属于哪个组 [root@localhost ~]# chown www.www /code/ [root@localhost ~]# chown -R www.www /code/
【5】重定向 1 将原本要输出到屏幕的数据信息,重新定向到指定的文件中。
1 2 3 4 5 6 1.当屏幕输出的信息很重要,而且希望保存重要的信息时。 2.后台执行中的程序,不希望他干扰屏幕正常的输出结果时。 3.系统的例行命令,例如定时任务的执行结果,希望他可以存下来时。 4.一些执行命令,我们已经知道他可能出现错误信息,想将他直接丢弃时。 5.执行一个命令,可能报错和正确的输出并存,类似错误日志与标准正确日志需要分别输出至不同的文件。
执行一个shell程序时通常会自动打开三个文件描述符
名称
文件描述符
作用
标准输入 (stdin)
0
通常是键盘,也可以是其他文件或者命令的输出的内容可以作为标准输入
标准输出 (stdout)
1
默认输出到屏幕
错误输出 (stderr)
2
默认输出到屏幕
文件名称 (filename)
3+
1 2 3 4 5 6 7 8 9 10 11 12 13 标准输入:stdin 标准输出:stdout 错误输出:stderr [root@localhost ~]# ll /dev/std* lrwxrwxrwx. 1 root root 15 Apr 16 15:52 /dev/stderr -> /proc/self/fd/2 lrwxrwxrwx. 1 root root 15 Apr 16 15:52 /dev/stdin -> /proc/self/fd/0 lrwxrwxrwx. 1 root root 15 Apr 16 15:52 /dev/stdout -> /proc/self/fd/1 文件描述符fd:一个命令或者程序在执行过程中,至少要打开4个文件描述符 文件描述符0:标准输入 文件描述符1:标准输出 文件描述符2:错误输出 文件描述符3+:文件名
输入输出
符号
标准输入重定向
< 或 0<
标准输出重定向
> 或 1>
错误输出重定向
2>
查看标准输入输出设备
1 2 3 4 [root@lb01 ~]# ll /dev/std* lrwxrwxrwx. 1 root root 15 Apr 16 08:16 /dev/stderr -> /proc/self/fd/2 错误输出 lrwxrwxrwx. 1 root root 15 Apr 16 08:16 /dev/stdin -> /proc/self/fd/0 标准输入 lrwxrwxrwx. 1 root root 15 Apr 16 08:16 /dev/stdout -> /proc/self/fd/1 标准输出
类型
操作符
用途
标准覆盖输出重定向
1>或>
将命令的执行结果输出到指定的文件中, 而不是直接显示在屏幕上
标准追加输出重定向
>>1或1>>
将命令执行的结果追加输出到指定文件
错误覆盖输出重定向
2>
将程序的错误结果输出到执行的文件中,会覆盖源文件内容
错误追加输出重定向
2>>
将程序输出的错误结果以追加的方式输出到指定文件中,不会覆盖源文件
标准输入重定向
<<
将命令中接收输入的途径由默认的键盘更改为指定的文件
1.重定向使用 1 2 3 4 5 6 7 8 9 标准输出追加重定向 [root@lb01 ~]# echo "111" >>1.txt 标准输出覆盖重定向 [root@lb01 ~]# echo "111" >1.txt 错误输出覆盖重定向 [root@lb01 ~]# nginx -V 2>> 1.txt 错误输出追加重定向 [root@lb01 ~]# nginx -V 2> 1.txt
==1.错误输出和正确输出,都输出到同一个文件中==
1 2 3 4 5 6 7 8 9 10 11 12 13 14 [root@lb01 ~]# find /etc/ -type d > /tmp/1.log 2>/tmp/1.log 标准输出到2.log 文件里,错误输出到和标准输出一样位置 [root@lb01 ~]# find /etc/ -type d 1> /tmp/2.log 2>&1 和上面相反 [root@lb01 ~]# find /etc/ -type d 2> /tmp/6.log 1>&2 [root@lb01 ~]# find /etc/ -type d &> /tmp/11.log [zls@localhost ~]$ find /etc/ -type d 1> /tmp/6.log 2>/dev/null 标准输出到6.log ,错误输出到黑洞 [zls@localhost ~]$ find /etc/ -type d &>/dev/null 所有输出结果到黑洞
==2.标准输出和错误输出到两个文件==
1 find /etc -name "*.conf" 1>a 2>b
==3.将标准输出和标准错误输出重定向到同一个文件, 混合输出==
1 2 3 4 5 [zls@zls ~]$ find /etc -name "*.conf" &>ab [zls@zls ~]$ find /etc -name "*.conf" >ab 2&>1 [zls@zls ~]$ find /etc -name "*.conf" >ab 2>&1 合并两个文件到一个文件 cat 1 2 >3
2.输入重定向 输入重定向,即原本从键盘等设备上获得的输入信息,重定向由命令的输出作为输入
1 2 3 4 5 6 7 8 [root@localhost ~]# cat >1.txt 等待键盘输入重定向到1.txt,Ctrl+c终止输入 [root@localhost ~]# cat <<EOF > 1.txt 等待键盘输入,遇到Eof结束重定向到1.txt 111 222 333 EOF
3.两条命令重定向 1 2 3 4 5 6 7 8 9 10 [root@localhost ~]# (ls ;ifconfig) > /tmp/1.txt [root@localhost ~]# ping baidu.com &>/tmp/a.log & 扩展点: subshell [root@zls ~]# cd /boot; ls [root@zls ~]# (cd /boot; ls )
4.管道技术 1 2 3 管道符作用:将管道符左边命令的标准输出交给管道符右边命令的标准输入来处理 1)左边命令他得是标准输出 1> 2)右边命令必须有标准输入
==tee管道技术==
1 2 3 4 5 tee 相当于开个侧门输出重定向到某个文件,原理见上图[root@localhost ~]# echo $RANDOM |tee /dev/pts/3|passwd --stdin zls [root@localhost ~]# echo $RANDOM |tee /tmp/pass.txt|passwd --stdin zls [root@localhost ~]# echo $RANDOM |tee -a /tmp/pass.txt|passwd --stdin zls
5.xargs传参 xaras后面不识别别名
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 xargs将管道符前面命令的标准输出,当成结果,放到管道符右边xargs后面的命令的后面执行 [root@localhost ~]# echo {1..10} 1 2 3 4 5 6 7 8 9 10 [root@localhost ~]# echo {1..5}|xargs -n1 1 2 3 4 5 [root@localhost ~]# echo {1..10}|xargs -n2 -n2每两个一行 -n3每三个拍一行 1 2 3 4 5 6 7 8 9 10 [root@lb01 ~]# seq 10|xargs -n3 1 2 3 4 5 6 7 8 9 10 [root@localhost ~]# grep -rl 'xxx' ./|xargs cp -t /tmp/ [root@localhost ~]# grep -rl 'xxx' ./|xargs -I {} cp {} /opt 注意事项: 1.在管道后面的命令,都不应该在写文件名 2.在管道中只有标准输出才可以传递下一个命令, 标准错误输出会直接输出终端显示, 建议在使用管 道前将标准错误输出重定向。 例如: find /etc -name "*.conf" 2>/dev/null | grep rc 3.有些命令不支持管道技术, 但是可以通过 xargs 来实现管道传递。 例如: which cat |xargs ls-l 例如: ls |xargs rm -rvf -I 选项作用是将前面输出结果打包到{}内 例如: ls |xargs cp -rvft /tmp/ ==> ls | xargs -I {} cp -rvf {} /tmp 例如: ls |xargs mv -t /tmp/ ==> ls | xargs -I {} mv {} /tmp
xargs选项
作用
-a
设置从文件中读取数据
-d
设置自定义定界符
-l
设置替换字符串
-n
设置多行输出
-p
执行命令前询问用户是否确认
-r
如果输入数据为空,则不执行
-s
设置每条命令最大字符数
-t
显示xargs执行的命令
【6】文件解压缩 1.常见压缩包类型
格式
压缩工具
.zip
zip压缩工具
.gz
gzip压缩工具,只能压缩文件,会删除源文件(通常配合tar使用)
bz2
bzip2压缩工具,只能压缩文件,会删除源文件(通常配合tar使用)
.tar.gz
先使用tar命令归档打包,然后使用gzip压缩
tar.bz2
先使用tar命令归档打包,然后使用bzip2压缩
2.压缩解压命令—gzip 注意:
1 2 3 4 使用打包压缩命令,最好到需要被打包目录的上级目录, 解压时,-C最好不要指定/目录 可能会覆盖/下某些原文件 [root@localhost ~]# tar xf mysql.tgz -C / /etc/profile
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 语法:gzip 文件名 [root@localhost ~]# gzip file1 [root@driver-zeng ~]# echo 22222|gzip > zls.txt.gz [root@localhost ~]# gzip -d file1.gz [root@localhost ~]# file file2.gz file2.gz: gzip compressed data, was "file2" , from Unix, last modified: Thu Apr 18 17:33:26 2024 [root@localhost ~]# zcat file4.gz xxx 1.压缩包后缀.gz 2.压缩后源文件不存在 3.压缩率很高 4.缺陷就是,不能压缩目录,不能压缩多个文件 5.解压后,压缩包不在了,源文件出来了 6.可以直接使用命令查看压缩包中文件的内容
3.压缩解压命令—zip 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 [root@localhost ~]# yum install -y zip zip 包名 文件名... [root@localhost ~]# zip file1.zip file1 [root@localhost ~]# zip file.zip file1 file10 [root@localhost ~]# file file.zip file.zip: Zip archive data, at least v1.0 to extract [root@localhost ~]# zip -r dir1.zip dir1/ [root@localhost ~]# zip -r /tmp/test.zip test / [root@localhost ~]# yum install -y unzip [root@localhost opt]# unzip dir1.zip [root@localhost tmp]# unzip /opt/dir1.zip 解压指定目录文件 [root@localhost local ]# unzip -l /opt/dir1.zip Archive: /opt/dir1.zip Length Date Time Name --------- ---------- ----- ---- 0 04-18-2024 18:40 dir1/ 26 04-18-2024 18:40 dir1/file1.gz 27 04-18-2024 18:40 dir1/file10.gz 26 04-18-2024 18:40 dir1/file2.gz 26 04-18-2024 18:40 dir1/file3.gz 26 04-18-2024 18:40 dir1/file4.gz 261 11 files 1.压缩包后缀.zip 2.压缩后源文件存在 3.压缩率很高 4.默认情况下不能压缩目录,能压缩多个文件,压缩目录需要选项 5.压缩时可以指定压缩包的路径 6.解压后,压缩包还在,源文件出来了 7.不可以直接使用命令查看压缩包中文件的内容
4.压缩解压命令—tar
选项
作用
c
创建归档文件
f
指定归档文件的包名
z
使用gzip来压缩归档后的文件,xf解压.tar.gz包
x
对归档文件进行解压
v
显示过程
t
查看压缩包中的所有文件和目录
X
可以排除多个不想打包的文件,指定文件名 (把不想打包的文件名写入一个文件,X指定这个文件就行,若排除的文件在嵌套目录,则把相对路径写上即可)
h
打包软链接的源文件
J
使用xz压缩归档后的文件,xf 解压.tar.xz包
-P
使用绝对路径打包
j
使用bzip2压缩归档后的文件,xf解压 .tar.bz2包
-C
解压到指定目录
—exclude
排除不想要的文件
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 tar [选项] 包名 文件... [root@localhost ~]# file abc.tar abc.tar: POSIX tar archive (GNU) [root@localhost ~]# file nginx-1.22.1.tar.gz nginx-1.22.1.tar.gz: gzip compressed data, from Unix, last modified: Wed Oct 19 16:02:28 2022 [root@localhost ~]# tar cf dir1.tar dir1 [root@localhost ~]# tar cf /tmp/dir1_xxx.tar dir1 [root@localhost ~]# tar zcf dir1.tgz dir1/ [root@localhost ~]# tar zcvf dir1.tgz dir1/ [root@localhost ~]# tar zxf dir1.tgz [root@localhost ~]# tar tf nginx-1.22.1.tar.gz [root@localhost ~]# tar zxf nginx-1.22.1.tar.gz -C /tmp/ [root@localhost tmp]# tar zcf root2.tgz --exclude=file6 --exclude=file7 /root 1.归档包后缀.tar 2.归档后源文件存在 3.没有压缩率 4.默认情况下能归档目录,能归档多个文件 5.归档时可以指定归档的路径 6.解压后,压缩包还在,源文件出来了 7.不可以直接使用命令查看压缩包中文件的内容
1 2 [root@localhost abc]# tar czf - ./ | tar xzf - -C /tmp
【7】软件安装 1.rpm包 ==RPM包名==
1 2 tree- 1.6.0 - 10 . el7 . x86_64 .rpm 包名 版本号 发布了10次 适用于7系系统 系统架构 文件后缀
分类
安装
版本
rpm包(需要安装)
预先编译打包,安装简单
软件版本偏低
源码包(需要编译、安装)
手动编译打包,安装繁琐
软件版本最新
二进制包(绿色免安装软件)
解压即可使用, 安装简单
版本跟官方保持一致,不能修改源码
注意: 不管是源码包,还是rpm包,安装时都可能会有依赖关系 1. 获取RPM包 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 1.RedHat光盘或官方网站 (通过挂载的方式访问) [root@localhost ~]# mount /dev/cdrom /mnt mount挂载虚拟机设置镜像保持连接状态 mount: /dev/sr0 is write-protected, mounting read-only [root@localhost ~]# ls -1 /mnt/Packages/|wc -l ls -1查看内容竖向排列 4022 df -h 可以查看挂载情况[root@lb01 ~]# df -h Filesystem Size Used Avail Use% Mounted on /dev/sda3 19G 1.6G 18G 9% / devtmpfs 476M 0 476M 0% /dev tmpfs 487M 0 487M 0% /dev/shm tmpfs 487M 7.6M 479M 2% /run tmpfs 487M 0 487M 0% /sys/fs/cgroup /dev/sda1 497M 120M 378M 25% /boot tmpfs 98M 0 98M 0% /run/user/0 /dev/sr0 4.3G 4.3G 0 100% /mnt 2.RPM包官网 http://rpmfind.net/ 以后报错中,libCHARSET3-samba4.so .so结尾的文件不存在,需要安装,不知道输入哪个RPM包,去RPM官网查询即可 mysql:https://www.mysql.com/ nginx:https://www.nginx.org/ 阿里云:https://developer.aliyun.com/mirror/ 网易镜像站:https://mirrors.163.com/ 华为源:https://mirrors.huaweicloud.com/ 清华源:https://mirrors.tuna.tsinghua.edu.cn/ 中科大:https://mirrors.ustc.edu.cn/
2.RPM包管理 ① 安装 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 rpm [选项] 安装包名 i:install 安装 v:显示安装过程 h:显示进度条 --test :检测是否能安装成功 --force:强制安装 --nodeps:忽略依赖关系 [root@localhost Packages]# rpm -i tree-1.6.0-10.el7.x86_64.rpm [root@localhost ~]# rpm -ivh /mnt/Packages/unzip-6.0-19.el7.x86_64.rpm [root@localhost Packages]# rpm -i https://mirrors.aliyun.com/centos/7.9.2009/os/x86_64/Packages/tree-1.6.0-10.el7.x86_64.rpm [root@localhost Packages]# rpm -ivh https://mirrors.aliyun.com/centos/7.9.2009/os/x86_64/Packages/tree-1.6.0-10.el7.x86_64.rpm 显示进度条和安装过程
② 查询 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 -q: query 查询 -qa:查询系统内所有安装过的包 -ql:查询软件包安装完后,配置文件、帮助文档、程序....的所在目录([# rpm -ql nginx) -qc:查询软件安装后配置文件 conf配置文件 (# rpm -qc nginx) -qf:逆向查询,根据文件名,可以查出该文件是安装了哪个RPM包 (需要完整目录)(# rpm -qf /usr/sbin/nginx) 1.[root@localhost ~]# rpm -qi $(rpm -qf /etc/redhat-release) 2.[root@localhost ~]# rpm -qf /etc/redhat-release|xargs rpm -qi 3.[root@localhost ~]# rpm -qif /etc/redhat-release ---- [root@localhost ~]# rpm -q --scripts nginx ---- -qi:查看已安装安装包的详细信息 (后面跟包名) -qd:查看帮助文档位置 -qip:可以查看未安装的包详细信息 前提:得有这个包 [root@localhost ~]# rpm -qip /mnt/Packages/zip-3.0-11.el7.x86_64.rpm -qlp:可以查看未安装的包,安装后会产生哪些文件 [root@localhost ~]# rpm -qlp /mnt/Packages/zip-3.0-11.el7.x86_64.rpm /usr/bin/zip /usr/bin/zipcloak /usr/bin/zipnote /usr/bin/zipsplit /usr/share/doc/zip-3.0 /usr/share/doc/zip-3.0/CHANGES /usr/share/doc/zip-3.0/LICENSE [root@localhost ~]# rpm -q tree // 安装过了 tree-1.6.0-10.el7.x86_64 [root@localhost ~]# rpm -q tree // 没有安装 package tree is not installed [root@localhost ~]# rpm -qa|grep tree tree-1.6.0-10.el7.x86_64 [root@localhost ~]# rpm -qa|grep mysql [root@localhost ~]# rpm -qa|grep nginx [root@localhost ~]# rpm -qi tree Name : tree Version : 1.6.0 Release : 10.el7 Architecture: x86_64 Install Date: Fri 19 Apr 2024 08:05:31 PM CST Group : Applications/File Size : 89505 License : GPLv2+ Signature : RSA/SHA256, Fri 04 Jul 2014 01:36:46 PM CST, Key ID 24c6a8a7f4a80eb5 Source RPM : tree-1.6.0-10.el7.src.rpm Build Date : Tue 10 Jun 2014 03:28:53 AM CST Build Host : worker1.bsys.centos.org Relocations : (not relocatable) Packager : CentOS BuildSystem <http://bugs.centos.org> Vendor : CentOS URL : http://mama.indstate.edu/users/ice/tree/ Summary : File system tree viewer Description : The tree utility recursively displays the contents of directories in a tree-like format. Tree is basically a UNIX port of the DOS tree utility. [root@localhost ~]# rpm -qc nginx /etc/logrotate.d/nginx /etc/nginx/fastcgi.conf /etc/nginx/fastcgi.conf.default /etc/nginx/fastcgi_params /etc/nginx/fastcgi_params.default /etc/nginx/koi-utf /etc/nginx/koi-win /etc/nginx/mime.types /etc/nginx/mime.types.default /etc/nginx/nginx.conf /etc/nginx/nginx.conf.default /etc/nginx/scgi_params /etc/nginx/scgi_params.default /etc/nginx/uwsgi_params /etc/nginx/uwsgi_params.default /etc/nginx/win-utf [root@localhost ~]# rpm -qf /etc/hosts setup-2.8.71-10.el7.noarch [root@localhost ~]# rpm -qf /usr/sbin/ifconfig net-tools-2.0-0.25.20131004git.el7.x86_64
③卸载 1 2 [root@localhost ~]# rpm -e tree
④升级RPM包 1 2 3 4 -U 如果老版本不存在,就全新安装,如果存在有新版即升级 -f 老版本必须存在 [root@localhost ~]# rpm -fvh tree-1.8.0-2.mga8.x86_64.rpm [root@localhost ~]# rpm -Uvh tree-1.8.0-2.mga8.x86_64.rpm
==总结==
1 2 3 4 5 6 7 缺陷 1.rpm包管理无法解决包与包之间的依赖关系 2.rpm包的查询,基本上都需要已经安装过的包 优点: 1.不需要网络安装 2.安装速度快
2.yum工具 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 1.联网获取软件 2.基于RPM管理 3.自动解决依赖(前提:1.yum仓库中必须有该依赖包 2.版本要一致) 4.命令简单好记 5.生产最佳实践 yum是RedHat以及CentOS中的软件包管理器,能够通过互联网下载以rpm结尾的包,并且安装,并可以自动 处理依赖性关系,无需繁琐的一次次下载安装。 yum仓库 | yum源 yum install -y xx dnf install xxx Base源 - Base源 基础包 - epel源 扩展包
==配置yum源==
1 2 3 4 5 6 各大镜像源: 阿里云:https://opsx.alibaba.com/mirror 清华源:https://mirrors.tuna.tsinghua.edu.cn/ 163源:http://mirrors.163.com/ 华为源:https://mirrors.huaweicloud.com/ 科大源:http://mirrors.ustc.edu.cn/
==配置Base源==
1 2 3 4 5 6 7 8 9 10 11 12 13 14 [root@lb01 ~]# ll /etc/yum.repos.d/ yum源配置文件 wget -O:指定保存的路径和文件名 https://mirrors.aliyun.com/repo/Centos-7.repo curl -o = wget -O 1)清空/etc/yum.repos.d下面所有源配置文件(mv rm ) [root@localhost ~]# mv /etc/yum.repos.d/*.repo /tmp/ [root@localhost ~]# gzip /etc/yum.repos.d/* 2)下载国内各大镜像站源 wget -O /etc/yum.repos.d/CentOS-Base.repo https://mirrors.aliyun.com/repo/Centos-7.repo curl -o /etc/yum.repos.d/CentOS-Base.repo https://mirrors.aliyun.com/repo/Centos-7.repo
① 换源 1 2 3 4 5 6 7 8 wget -O /etc/yum.repos.d/CentOS-Base.repo https://mirrors.aliyun.com/repo/Centos-vault-8.5.2111.repo sed -e 's|^mirrorlist=|#mirrorlist=|g' \ -e 's|^#baseurl=http://mirror.centos.org/centos|baseurl=https://mirrors.tuna.tsinghua.edu.cn/centos|g' \ -i.bak \ /etc/yum.repos.d/CentOS-*.repo
==更换epel源==
1 2 3 4 5 [root@localhost ~]# curl -o /etc/yum.repos.d/epel.repo https://mirrors.aliyun.com/repo/epel-7.repo [root@localhost ~]# ll /etc/yum.repos.d/ total 8 -rw-r--r--. 1 root root 1759 Apr 22 18:55 CentOS-Base.repo -rw-r--r--. 1 root root 664 Apr 22 19:08 epel.repo
② yum管理命令 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 [root@yum_repo ~]# yum provides pstree 注意:yum provides命令只能用于已经安装的软件包 [root@yum_repo ~]# yum search pstree [root@localhost ~]# yum list [root@localhost ~]# yum list|grep net-tools [root@localhost ~]# yum info 包名 [root@localhost ~]# yum info tree [root@lb01 yum.repos.d]# yum repolist Loaded plugins: fastestmirror Loading mirror speeds from cached hostfile repo id repo name status base/7/x86_64 CentOS-7 - Base - mirrors.huaweicloud.com 10,072 extras/7/x86_64 CentOS-7 - Extras - mirrors.huaweicloud.com 526 updates/7/x86_64 CentOS-7 - Updates - mirrors.huaweicloud.com 5,802 repolist: 16,400 repolist: 30,679 [root@localhost ~]# yum repolist all
③ yum安装命令 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 [root@localhost ~]# yum install 包名 [root@localhost ~]# yum install vim Is this ok [y/d/N]: 输入y:yes 安装 输入d:download 仅下载不安装 输入N:No不安装 [root@localhost ~]# yum install vim -y [root@localhost ~]# yum -y install vim [root@localhost ~]# yum install -y vim [root@localhost ~]# yum install vim [root@localhost Packages]# yum localinstall -y wget-1.14-18.el7.x86_64.rpm [root@localhost Packages]# yum install -y http://test.driverzeng.com/MySQL_plugins/mha4mysql-node-0.56-0.el6.noarch.rpm [root@localhost ~]# yum install --downloadonly --downloaddir=/opt/ nginx
④ yum重装/更新/删除 1 2 3 4 5 6 7 8 9 10 11 12 13 [root@localhost nginx]# yum reinstall -y nginx [root@localhost nginx]# yum check-update [root@localhost nginx]# yum update acl -y [root@localhost nginx]# yum update -y [root@localhost nginx]# yum remove -y tree [root@localhost nginx]# yum erase -y tree
④ yum逆向查询/缓存 1 2 3 4 5 6 7 8 [root@localhost nginx]# yum provides */ifconfig [root@localhost nginx]# yum makecache [root@localhost nginx]# yum clean all
⑤ 爬取rpm包 1 https://mirrors.aliyun.com/zabbix/zabbix/5.0/rhel/7/x86_64/?spm=a2c6h.25603864.0.0.239b5d4a bvLbEB
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 1.指定下载目录 [root@lb01 ~]# curl -s https://mirrors.aliyun.com/zabbix/zabbix/5.0/rhel/7/x86_64/?spm=a2c6h.25603864.0.0.239b5d4a bvLbEB|awk -F '"' '/rpm/{print "mkdir -p /repo/zabbix/;wget -O /repo/zabbix/"$4" https://mirrors.aliyun.com/zabbix/zabbix/5.0/rhel/7/x86_64/"$4}' |bash 2.下载到当前目录 [root@lb01 ~]# curl -s https://mirrors.aliyun.com/zabbix/zabbix/5.0/rhel/7/x86_64|awk -F '"' '/rpm/{print $4}' |sed 's#zabbix#https://mirrors.aliyun.com/zabbix/zabbix/5.0/rhel/7/x86_64/zabbix#g' |xargs wget 1.curl 网站获取网页内容 [root@lb01 ~]# curl -s https://mirrors.aliyun.com/zabbix/zabbix/5.0/rhel/7/x86_64 2.截取所有rpm包名 [root@lb01 ~]# curl -s https://mirrors.aliyun.com/zabbix/zabbix/5.0/rhel/7/x86_64|awk -F '"' '/rpm/{print $4}' zabbix-agent-5.0.0-1.el7.x86_64.rpm zabbix-agent-5.0.1-1.el7.x86_64.rpm zabbix-agent-5.0.10-1.el7.x86_64.rpm zabbix-agent-5.0.11-1.el7.x86_64.rpm 3.补全公共下载链接https://mirrors.aliyun.com/zabbix/zabbix/5.0/rhel/7/x86_64/?spm=a2c6h.25603864.0.0.239b5d4a bvLbEB sed 's#zabbix#https://mirrors.aliyun.com/zabbix/zabbix/5.0/rhel/7/x86_64/zabbix#g' 4.拼接命令交给wget [root@lb01 ~]# curl -s https://mirrors.aliyun.com/zabbix/zabbix/5.0/rhel/7/x86_64|awk -F '"' '/rpm/{print $4}' |sed 's#zabbix#https://mirrors.aliyun.com/zabbix/zabbix/5.0/rhel/7/x86_64/zabbix#g' |xargs wget
3.yum文件&命令 ① yum程序的配置文件 1 2 3 4 5 6 7 8 9 10 11 12 13 [root@localhost ~]# cat /etc/yum.conf cachedir=/var/cache/yum/$basearch /$releasever //缓存目录 keepcache=0 //缓存软件包, 1启动 0 关闭 debuglevel=2 //调试级别 logfile=/var/log/yum.log //日志记录位置 exactarch=1 //检查平台是否兼容 obsoletes=1 //检查包是否废弃 gpgcheck=1 //检查来源是否合法,需要有制作者的公钥信息 plugins=1 //是否启用查询 installonly_limit=5 bugtracker_url
②yum组命令 1 2 3 4 5 6 7 [root@localhost ~]# yum groups list [root@localhost ~]# yum groups install Development tools Compatibility libraries Base Debugging Tools [root@localhost ~]# yum groups remove -y Base
③ yum历史命令 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 [root@localhost ~]# yum history Loaded plugins: fastestmirror ID | Login user | Date and time | Action(s) | Altered ------------------------------------------------------------------------------- 6 | root <root> | 2024-04-23 18:05 | Install | 1 5 | root <root> | 2024-04-23 17:09 | Update | 2 4 | root <root> | 2024-03-26 17:36 | Install | 1 3 | root <root> | 2024-03-26 17:31 | Install | 1 2 | root <root> | 2024-03-22 15:55 | Install | 1 1 | System <unset > | 2024-03-21 20:50 | Install | 308 [root@localhost ~]# yum history info 6 Loaded plugins: fastestmirror Transaction ID : 6 Begin time : Tue Apr 23 18:05:41 2024 Begin rpmdb : 311:bc74a8339d5853ce2035d376bffbbeeb40d44ae3 End time : 18:05:42 2024 (1 seconds) End rpmdb : 312:44280ba9419b586ea77d5fa483785725fe7e9758 User : root <root> Return-Code : Success Command Line : install -y tree Transaction performed with: Installed rpm-4.11.3-35.el7.x86_64 @anaconda Installed yum-3.4.3-161.el7.centos.noarch @anaconda Installed yum-plugin-fastestmirror-1.1.31-50.el7.noarch @anaconda Packages Altered: Install tree-1.6.0-10.el7.x86_64 @base history info[root@localhost ~]# yum history undo 6 -y
4.制作yum仓库 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 条件: 1.制作仓库,一定要有存放rpm包的目录 2.会配置repo仓库文件 [base] name=CentOS-$releasever - Base - mirrors.aliyun.com baseurl=http://mirrors.aliyun.com/centos/$releasever /os/$basearch / gpgcheck=1 // 0 代表关闭,不检测 1 代表开启,检测 gpgkey=http://mirrors.aliyun.com/centos/RPM-GPG-KEY-CentOS-7 enabled=0 // 是否开启该仓库,0代表关闭 1代表开启 钥匙 锁 - http:// 远程协议 - https:// 远程协议 - ftp:// 远程协议 - file:// 本地协议,只能访问本机
① 制作本地yum仓库 1 2 3 4 5 6 7 8 9 10 11 12 [root@localhost ~]# yum install -y createrepo [root@localhost ~]# createrepo /repo/zabbix/ Spawning worker 0 with 475 pkgs [root@localhost yum.repos.d]# vim zls.repo [zls_repo] name=zls's yum repository xxxx baseurl=file:///repo/zabbix/ gpgcheck=0 enabled=1
==如何在仓库中新加RPM包==
1 2 3 4 5 6 wget cp mv ... [root@localhost repo]# createrepo --update /repo [root@localhost ~]# yum makecache
需求:将/dev/cdrom中的rpm包,拷贝到 /zls/base目录下,然后将该目录制作成本地的yum仓库
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 [root@localhost ~]# mkdir -p /zls/base [root@localhost ~]# mount /dev/cdrom /mnt [root@localhost ~]# cp /mnt/Packages/*.rpm /zls/base/ [root@localhost ~]# createrepo /zls/base/ [root@localhost ~]# vi /etc/yum.repos.d/zls.repo [zls_repo] name=zls's yum repository xxxx baseurl=file:///repo/ gpgcheck=0 enabled=1
② 制作远程yum仓库 环境准备
主机
ip
角色
yum_repo
10.0.0.101
yum仓库
web01
10.0.0.102
使用yum仓库的机器
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 - http:// 远程协议 - https:// 远程协议(别考虑) - ftp:// 远程协议 [root@web01 ~]# hostnamectl set-hostname yum_repo [root@web01 ~]# hostnamectl set-hostname web01 [root@yum_repo ~]# systemctl stop firewalld [root@web01 ~]# systemctl stop firewalld [root@web01 ~]# setenforce 0 [root@web01 ~]# getenforce Permissive
ftp制作远程仓库 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 [root@yum_repo ~]# yum install -y vsftpd [root@yum_repo ~]# systemctl start vsftpd [root@yum_repo ~]# systemctl enable vsftpd [root@yum_repo pub]# rpm -ql vsftpd|grep pub /var/ftp/pub [root@yum_repo pub]# mount /dev/cdrom /mnt/ [root@yum_repo pub]# cp /mnt/Packages/tree-1.6.0-10.el7.x86_64.rpm /mnt/Packages/wget-1.14-18.el7.x86_64.rpm base/ [root@yum_repo ~]# yum install -y createrepo [root@yum_repo ~]# createrepo /var/ftp/pub/base/ Spawning worker 0 with 2 pkgs Workers Finished Saving Primary metadata Saving file lists metadata Saving other metadata Generating sqlite DBs Sqlite DBs complete [root@yum_repo base]# vim zls_base.repo [zls_base_repo] name=test baseurl=ftp://10.0.0.101/pub/base/ gpgcheck=0 enabled=1 [root@web01 ~]# curl -o /etc/yum.repos.d/zls_base.repo ftp://10.0.0.101/pub/base/zls_base.repo [root@web01 ~]# vim /etc/yum.repos.d/xxx.repo [zls_base_repo] name=test baseurl=ftp://10.0.0.101/pub/base/ gpgcheck=0 enabled=1
nginx制作远程仓库 环境准备
主机
ip
角色
yum_repo
10.0.0.101
yum仓库
web01
10.0.0.102
使用yum仓库的机器
前期准备
1 2 3 4 5 6 7 8 9 10 11 12 [root@web01 ~]# hostnamectl set-hostname yum_repo [root@web01 ~]# hostnamectl set-hostname web01 [root@yum_repo ~]# systemctl stop firewalld [root@web01 ~]# systemctl stop firewalld [root@web01 ~]# setenforce 0 [root@web01 ~]# getenforce Permissive
使用nginx制作yum仓库
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 [root@yum_repo ~]# yum -y install nginx [root@yum_repo ~]# systemctl start nginx [root@yum_repo ~]# systemctl enable nginx [root@yum_repo yum]# mkdir /etc/repo/yum/{base,zabbix} -p [root@yum_repo yum]# mkdir /etc/repo/yum/base/ -p [root@yum_repo yum]# mkdir /etc/repo/yum/zabbix/ -p [root@web01 ~]# mount /dev/cdrom /mnt/ [root@yum_repo yum]# cp /mnt/Packages/* /etc/repo/yum/base/ 拷贝爬取的zabbix的包到/etc/repo/yum/zabbix下 [root@lb01 nginx]# cp /repo/zabbix/* /etc/repo/yum/zabbix [root@yum_repo ~]# yum install -y createrepo [root@yum_repo yum]# createrepo /etc/repo/yum/base/ [root@yum_repo yum]# createrepo /etc/repo/yum/zabbix/ [root@yum_repo nginx]# vim /etc/nginx/nginx.conf location / { 45 autoindex on; 46 root /etc/repo/yum; 47 } server { listen 80; listen [::]:80; server_name _; root /usr/share/nginx/html; location / { autoindex on; root /etc/repo/yum; } } 这个前提是,nginx.confp配置文件里没有server{ }这个内容,相当于把这段命令写在conf.d配置文件里 server{ listen 80; server_name _; location /{ autoindex on; root /yum_repo; index index.html; } } [root@yum_repo ~]# nginx -t nginx: the configuration file /etc/nginx/nginx.conf syntax is ok nginx: configuration file /etc/nginx/nginx.conf test is successful [root@yum_repo ~]# systemctl restart nginx [root@yum_repo base]# vim nginx.repo [nginx_repo] name=test baseurl=10.0.0.101/base/ gpgcheck=0 enabled=1 [nginx_repo] name=test baseurl=10.0.0.101/zabbix/ gpgcheck=0 enabled=1 可以将nginx.repo文件放在 /etc/repo/yum/目录下 下载制作的nginx.repo源 [root@web01 ~]# wget -O /etc/yum.repos.d/ http://10.0.0.101/nginx.repo 删除web01客户端其它源,只留nginx.repo源,使用安装rpm包测试我们制作的yum源
【8】进程管理 1 2 3 程序:它是一个静态的概念,开发人员写好的代码 进程:它是一个动态的概念,将程序运行起来的过程,就叫做进程 运行环境:能让程序正常运行的环境,对应开发语言写的代码,需要对应的环境来运行
注意:
1 2 1.当程序运行为进程后,系统会为该进程分配内存,以及运行的身份和权限。 2.在进程运行的过程中,服务器上会有各种状态来表示当前进程的指标信息。
进程的生命周期
1 2 3 4 5 6 7 8 9 10 11 12 - 等待: 1)有没有用户的新请求来 2)子进程是否处理完返回结果 1)处理请求 2)将结果返回给父进程 1)正常结束 2)僵尸进程 3)孤儿进程
僵尸进程
1 2 3 4 子进程比父进程先结束,父进程没有回收子进程的资源,此时的子进程就称为"僵尸进程" 子进程的结束和父进程的运行是异步的,父进程永远不知道子进程什么时候结束,子进程在结束时,父进程繁忙来不及Wait子进程则会导致,子进程变成"僵尸进程"
孤儿进程
1 2 3 4 父进程比子进程先结束,子进程还在执行任务,没有父进程管理,此时的子进程就称为"孤儿进程" 子进程的结束和父进程的运行是异步的,父进程永远不知道子进程什么时候结束,当父进程正常完成工作或其他原因被终止,则会导致,子进程变成"孤儿进程"
1 2 3 4 1.当父进程接收到任务调度时,会通过fork派生子进程来处理,那么子进程会集成父进程的衣钵。 2.子进程在处理任务代码时,父进程会进入等待的状态... 3.如果子进程在处理任务过程中,父进程退出了,子进程没有退出,那么这些子进程就没有父进程来管理了,就变成了孤儿进程。 4.每个进程都会有自己的PID号,(process id )子进程则PPID
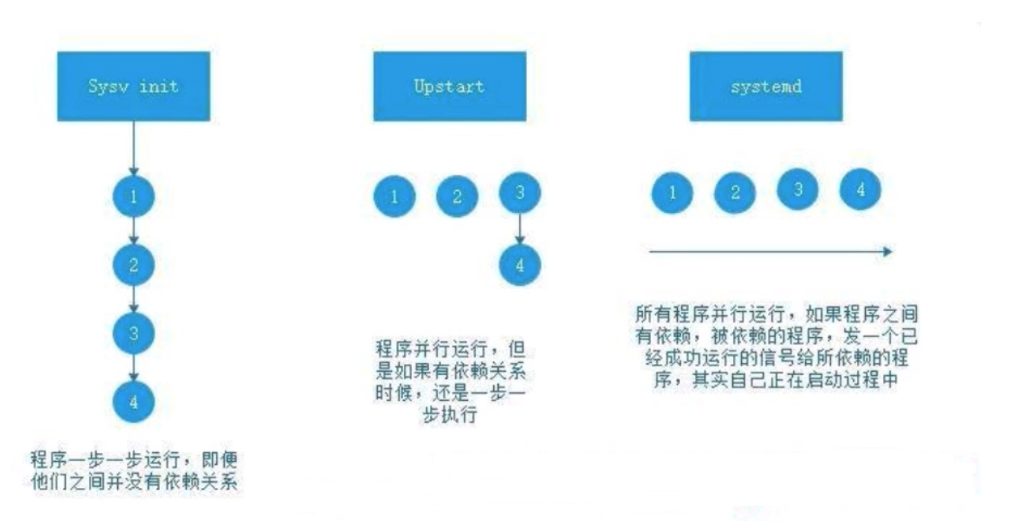
1.进程管理命令
拓展:查看服务进程状态,可用于脚本中,检查进程状态
① ps命令(静态) 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 [root@yum_repo ~]# ps aux [root@yum_repo ~]# ps -ef也可以 a:显示系统中所有和终端相关的进程 u:显示每个进程运行的用户 x:显示系统中所有和终端无关的进程 [root@yum_repo ~]# ps aux|head USER PID %CPU %MEM VSZ RSS TTY STAT START TIME COMMAND root 1 0.0 0.6 127864 6500 ? Ss 08:38 0:01 /usr/lib/systemd/systemd --switched-root --system --deserialize 22 root 2 0.0 0.0 0 0 ? S 08:38 0:00 [kthreadd] root 3 0.0 0.0 0 0 ? S 08:38 0:00 [ksoftirqd/0] root 5 0.0 0.0 0 0 ? S< 08:38 0:00 [kworker/0:0H] root 6 0.0 0.0 0 0 ? S 08:38 0:00 [kworker/u256:0] USER:运行程序的用户 PID:每个进程运行起来后,都会有自己的一个PID号,进程号Process ID %CPU:该进程占用CPU的百分比 %MEM:该进程占用内存的百分比 VSZ:该进程占用虚拟内存的大小 RSS:该进程占用真实内存的大小 TTY:终端 - ?:由内核发起的终端 - pts/0 pts/1:用户的虚拟终端 - tty1:物理终端 STAT:程序运行状态 START:服务启动的时间 TIME:该进程实际使用CPU的运行时间 COMMAND:服务运行起来的命令 D:无法中断的休眠状态(通IO的进程) 磁盘IO Input/Output 吞吐量(磁盘既写入又输出,例如tar打包数据时候) R:Running 正在运行的进程 S:Sleeping 处于休眠状态的进程 T:被暂停的进程状态 (Ctrl+z暂停进程) Z: 僵尸进程 <:优先级较高的进程 N:优先级较低的进程 s:父进程(并且它下面有子进程在运行) l:以线程的方式运行的进程 |:多进程 +:在前台运行的进程 L:被锁进内存页的进程 X:死掉的进程(少见) W:进入内存交换(从内核2.6开始无效)
② stat命令 介绍
应用
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 File: ‘/etc/passwd’ Size: 945 Blocks: 8 IO Block: 4096 regular file Device: fd00h/64768d Inode: 8902609 Links: 1 Access: (0644/-rw-r--r--) Uid: ( 0/ root) Gid: ( 0/ root) Context: system_u:object_r:passwd_file_t:s0 Access: 2024-04-21 21:52:14.512000577 +0800 Modify: 2024-04-20 13:49:48.339236224 +0800 Change: 2024-04-20 13:49:48.341236224 +0800 Birth: - [root@localhost ~]# stat -c%a /etc/passwd 644 [root@localhost ~]# stat -c%A /etc/passwd -rw-r--r-- [root@localhost ~]# stat -c%i /etc/passwd 8902609 [root@localhost ~]# stat -c%u /etc/passwd 0 [root@localhost ~]# stat -c%U /etc/passwd root [root@localhost ~]# stat -c%g /etc/passwd 0 [root@localhost ~]# stat -c%G /etc/passwd root [root@localhost ~]# stat -c%s /etc/passwd 945
1 2 3 4 5 6 7 [root@localhost ~]# stat -f /etc/passwd File: "/etc/passwd" ID: fd0000000000 Namelen: 255 Type: xfs Block size: 4096 Fundamental block size: 4096 Blocks: Total: 2361856 Free: 1896798 Available: 1896798 Inodes: Total: 4728832 Free: 4664790
1 2 3 4 5 6 7 -c后可以跟哪些占位符 stat -c %a file 显示文件的八进制权限stat -c %N file 显示完整路径stat -c %n file 显示文件名。stat -c %x file 显示最后访问时间stat -c %y file 显示最后修改时间stat -c "%n %s %y" filename.txt 这将输出文件名、文件大小和最后修改时间。
③ 内存/端口 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 free -h 以人类可读方式读取显示内存信息 [root@localhost ~]# netstat -lntup Active Internet connections (only servers) Proto Recv-Q Send-Q Local Address Foreign Address State PID/Program name tcp 0 0 0.0.0.0:22 0.0.0.0:* LISTEN 6866/sshd tcp 0 0 127.0.0.1:25 0.0.0.0:* LISTEN 6950/master tcp6 0 0 :::22 :::* LISTEN 6866/sshd tcp6 0 0 ::1:25 :::* LISTEN 6950/master
④ ps其他选项 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 [root@yum_repo ~]# ps aux|sort -k 4 -nr [root@yum_repo ~]# ps aux --sort %mem (默认占比最小的显示最前) [root@yum_repo ~]# ps axo user,pid,ppid,%mem,command ,%cpu 1.先查还有没有这个服务 [root@localhost ~]# ps aux|grep nginx root 10021 0.0 0.0 39304 940 ? Ss 16:44 0:00 nginx: master process /usr/sbin/nginx nginx 10022 0.0 0.1 39692 1896 ? S 16:44 0:00 nginx: worker process 2.使用端口号命令来查看该端口是否被监听。如果端口处于监听状态,则说明服务已经启动(nginx默认80端口,http协议) [root@lb01 ~]# netstat -lntup Active Internet connections (only servers) Proto Recv-Q Send-Q Local Address Foreign Address State PID/Program name tcp 0 0 0.0.0.0:80 0.0.0.0:* LISTEN 8752/nginx: master tcp 0 0 0.0.0.0:22 0.0.0.0:* LISTEN 6625/sshd tcp 0 0 127.0.0.1:25 0.0.0.0:* LISTEN 6708/master tcp6 0 0 :::80 :::* LISTEN 8752/nginx: master tcp6 0 0 :::22 :::* LISTEN 6625/sshd tcp6 0 0 ::1:25 :::* LISTEN 6708/master [root@lb01 ~]# netstat -tulun Active Internet connections (only servers) Proto Recv-Q Send-Q Local Address Foreign Address State tcp 0 0 0.0.0.0:80 0.0.0.0:* LISTEN [root@yum_repo ~]# ps aux |grep nginx|grep -v grep [root@yum_repo ~]# ps aux|grep nginx root 19740 0.0 0.1 39312 1044 ? Ss 12:00 0:00 nginx: master process /usr/sbin/nginx nginx 19741 0.0 0.1 39700 1816 ? S 12:00 0:00 nginx: worker process nginx 19742 0.0 0.1 39700 1816 ? S 12:00 0:00 nginx: worker process nginx 19759 0.0 0.1 39700 1816 ? S 12:00 0:00 nginx: worker process nginx 19760 0.0 0.1 39700 1556 ? S 12:00 0:00 nginx: worker process root 19823 0.0 0.0 112812 980 pts/2 R+ 12:05 0:00 grep -- color=auto nginx [root@yum_repo ~]# ps aux|grep [n]ginx grep nginx root 19823 0.0 0.0 112812 980 pts/2 R+ 12:05 0:00 grep -- color=auto [n]ginx [root@zls ~]# pgrep sshd 869 1194 1307 1574 [root@zls ~]# pgrep -l sshd 显示进程名及ID 869 sshd 1194 sshd 1307 sshd 1574 sshd [root@zls ~]# pgrep -l -a sshd 869 /usr/sbin/sshd -D 1194 sshd: root@pts/0 1307 sshd: root@pts/1 1574 sshd: root@pts/2 [root@zls ~]# pidof sshd 1574 1307 1194 869 [root@yum_repo ~]# pstree systemd─┬─NetworkManager───2*[{NetworkManager}] ├─VGAuthService ├─agetty ├─auditd───{auditd} ├─crond───crond───sh───ntpdate ├─dbus-daemon ├─gssproxy───5*[{gssproxy}] ├─nginx───20*[nginx] ├─polkitd───6*[{polkitd}]
⑤ top(动态命令) 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 top - 14:41:23 up 3:38, 1 user, load average: 0.00, 0.01, 0.05 top:命令 -:分隔符 09:32:57 :当前系统时间 up 1:23 :服务器运行时间 1 user :当前登录系统的用户数量 load average: 系统负载 0.00:1分钟 0.01:5分钟 0.05:15分钟 Tasks: 98 total, 1 running, 97 sleeping, 0 stopped, 0 zombie Tasks: 任务,进程数量 116 total // 进程总量 1 running // 1个正在运行的进程 R 115 sleeping // 115处于休眠状态的进程 S 0 stopped // 0个被暂停状态的进程 T 0 zombie // 0个僵尸进程 Z %Cpu(s): 0.0 us, 0.3 sy, 0.0 ni, 99.7 id , 0.0 wa, 0.0 hi, 0.0 si, 0.0 st %Cpu(s): 0.0 us:user 用户态 用户使用程序占用CPU的百分比 0.3 sy:system 内核态 系统使用程序占用CPU的百分比 0.0 ni:nice 优先级 优先级调度的进程占用CPU的百分比 99.7 id :idle 空闲 CPU的空闲率 0.0 wa: wait 等待 处于等待状态的进程占用CPU的百分比 0.0 hi: 硬中断 硬中断占用CPU的百分比 0.0 si: 软中断 软终端占用CPU的百分比 0.0 st: 虚拟化 虚拟化占用CPU的百分比 KiB Mem : 995896 total, 425312 free, 108804 used, 461780 buff/cache KiB Mem : 内存 995896 total:总内存大小 748564 free:空闲内存大小 107768 used:已使用内存大小 139564 buff/cache:缓冲区/缓存区使用内存大小 KiB Swap: 1048572 total, 1048572 free, 0 used. 700372 avail Mem KiB Swap: 交换分区swap (虚拟内存) 1048572 total:虚拟内存总大小 1048572 free:虚拟内存空闲大小 0 used:虚拟内存使用大小 729176 avail Mem:虚拟内存可用大小 Windows:NTFS、FAT32 Linux: CentOS7:xfs file system CentOS6:ext4 PID USER PR NI VIRT RES SHR S %CPU %MEM TIME+ COMMAND PID:进程ID号 USER:进程启动用户 PR NI:权重优先级 两者相差20,互斥 VIRT:虚拟内存 RES:真实物理内存 SHR:闪存 S:进程状态 %CPU:CPU使用率 %MEM:内存使用率 TIME+ :该进程在CPU内运行的时间 COMMAND:服务启动的命令
⑥ top命令的使用 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 [root@yum_repo ~]# yum install -y htop [root@yum_repo ~]# yum install -y glances [root@yum_repo ~]# top [root@yum_repo ~]# htop [root@yum_repo ~]# glances [root@yum_repo ~]# top -n 5 [root@yum_repo ~]# top -d 1 -n 5 [root@yum_repo ~]# top -p 1278 [root@yum_repo ~]# top -p $(pidof nginx|tr ' ' ',' ) [root@yum_repo ~]# top -d 1 -n 3 -b > /tmp/1.txt 注意:#不使用-b选项,只能写入最后一次的结果。top是动态的,只有结束才能够写入1.txt,结束的时候写入的也只是最后一次的结果 top -n 3 >1.txt h 查看帮出 z 高亮显示 1 显示所有CPU的负载 s 设置刷新时间 b 高亮现实处于R状态的进程 M 按内存使用百分比排序输出 P 按CPU使用百分比排序输出 R 对排序进行反转 f 自定义显示字段 k kill 掉指定PID进程 W 保存top环境设置 ~/.toprc q 退出
⑦ 中断 1 2 3 4 5 6 7 8 9 10 中断是系统用来影响硬件设备请求的一种机制,它会打断进程的正常调度和执行,然后调用内核中的中断处理程序来影响设备的请求 是为了让计算机可以处理更多的请求 会导致数据丢失 将中断,分为两个部分 硬中断:快速处理任务,临时保存在内存里 软中断:延迟处理未完成的任务
⑧ kill信号管理 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 [root@yum_repo ~]# kill -l 1) SIGHUP 2) SIGINT 3) SIGQUIT 4) SIGILL 5) SIGTRAP 6) SIGABRT 7) SIGBUS 8) SIGFPE 9) SIGKILL 10) SIGUSR1 11) SIGSEGV 12) SIGUSR2 13) SIGPIPE 14) SIGALRM 15) SIGTERM 16) SIGSTKFLT 17) SIGCHLD 18) SIGCONT 19) SIGSTOP 20) SIGTSTP 21) SIGTTIN 22) SIGTTOU 23) SIGURG 24) SIGXCPU 25) SIGXFSZ 26) SIGVTALRM 27) SIGPROF 28) SIGWINCH 29) SIGIO 30) SIGPWR 31) SIGSYS 34) SIGRTMIN 35) SIGRTMIN+1 36) SIGRTMIN+2 37) SIGRTMIN+3 38) SIGRTMIN+4 39) SIGRTMIN+5 40) SIGRTMIN+6 41) SIGRTMIN+7 42) SIGRTMIN+8 43) SIGRTMIN+9 44) SIGRTMIN+10 45) SIGRTMIN+11 46) SIGRTMIN+12 47) SIGRTMIN+13 48) SIGRTMIN+14 49) SIGRTMIN+15 50) SIGRTMAX-14 51) SIGRTMAX-13 52) SIGRTMAX-12 53) SIGRTMAX-11 54) SIGRTMAX-10 55) SIGRTMAX-9 56) SIGRTMAX-8 57) SIGRTMAX-7 58) SIGRTMAX-6 59) SIGRTMAX-5 60) SIGRTMAX-4 61) SIGRTMAX-3 62) SIGRTMAX-2 63) SIGRTMAX-1 64) SIGRTMAX 先关闭服务,再开启服务 只重新读取配置文件,不会停止服务 [root@yum_repo ~]# kill -1 8582 [root@yum_repo ~]# kill -HUP 8582 [root@yum_repo ~]# kill -2 8779 [root@yum_repo ~]# kill -INT 8779 [root@yum_repo ~]# systemctl stop nginx [root@yum_repo ~]# kill -3 8582 [root@yum_repo ~]# kill -QUIT 8582 [root@yum_repo ~]# kill -9 8847 [root@yum_repo ~]# kill -KILL 8847 [root@yum_repo ~]# kill 1122 [root@yum_repo ~]# kill -15 1122 [root@yum_repo ~]# kill -TERM 1122 [root@yum_repo ~]# kill -18 8870 [root@yum_repo ~]# kill -19 8884 [root@yum_repo ~]# kill -20 8896
2.优先级&负载 1.进程优先级 1 2 3 4 作用:可以让优先级高的进程,优先使用系统资源,内存、CPU、磁盘、文件描述符... nice 值越高:表示优先级越低,例如19,该进程容易将CPU使用量让给其他进程。nice 值越低:表示优先级越高,例如-20,该进程更不倾向于让出CPU。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 [root@localhost ~]# top -n 1 -p 6884 [root@localhost ~]# ps axo pid,user,nice ,command |grep sshd [root@localhost ~]# nice -n 优先级(-20 ~ 20) 程序启动命令(systemctl不行) [root@localhost ~]# systemctl start nginx [root@localhost ~]# ps -ef|grep nginx root 10691 1 0 18:08 ? 00:00:00 nginx: master process /usr/sbin/nginx [root@localhost ~]# systemctl stop nginx [root@localhost ~]# nice -n -15 /usr/sbin/nginx [root@localhost ~]# ps -ef|grep nginx [root@localhost ~]# netstat -lntup|grep nginx tcp 0 0 0.0.0.0:80 0.0.0.0:* LISTEN 10770/nginx: master tcp6 0 0 :::80 :::* LISTEN 10770/nginx: master [root@localhost ~]# top -p 10770 PID USER PR NI VIRT RES SHR S %CPU %MEM TIME+ COMMAND 10770 root 5 -15 39304 1068 124 S 0.0 0.1 0:00.00 nginx
Linux假死
1 2 3 4 5 6 不一定 ping协议:icmp 原因:ping 通,只能能说明icmp协议是通的,不能说明ssh协议是通的 不一定 ping协议:icmp
2.Linux后台进程管理 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 [root@localhost ~]# ping baidu.com & [root@localhost ~]# ping baidu.com >> /tmp/1.txt & [root@localhost ~]# nohup ping baidu.com & // 在当前目录下生成一个nohup.out文件, 所有输出结果会放入该文件 [root@localhost ~]# ping baidu.com Ctrl + Z // 将程序暂停到后台 bg // 将暂停的程序放入后台运行fg // 将暂停的程序调到前台运行 根据编号,调用指定的进程到前台jobs // 查看后台暂停的程序有哪些[root@localhost ~]# yum install -y screen [root@localhost ~]# screen -ls [root@localhost ~]# screen -list There are screens on: 11050.sina (Detached) [root@localhost ~]# screen // 没有命名的卷轴 [root@localhost ~]# screen -S baidu // 指定名字 Ctrl + a + d [root@localhost ~]# screen -S sina -X quit
3.系统平均负载 每次发现系统变慢时,我们通常做的第一件事,就是执行top或者uptime命令,来了解系统的负载情况。平均负载与CPU使用率并没有直接关系。
1 2 3 4 5 6 7 [root@localhost ~]# w 19:36:06 up 3:36, 3 users , load average: 0.00, 0.01, 0.05 [root@localhost ~]# uptime 19:36:10 up 3:36, 3 users , load average: 0.00, 0.01, 0.05 [root@localhost ~]# top -n 1 top - 19:36:15 up 3:36, 3 users , load average: 0.00, 0.01, 0.05
**平均负载是指,单位时间内,系统处于可运行状态和不可中断状态的平均进程数,也就是平均活跃进程数**
可运行状态和不可中断状态是什么?
1 2 1.可运行状态进程,是指正在使用CPU或者正在等待CPU的进程,也就是我们用PS命令看的处于R状态的进程 2.不可中断进程,(你在做什么事情的时候是不能被打断的呢?...不可描述)系统中最常见的是等待硬件设备的IO相应,也就是我们PS命令中看到的D状态(也成为Disk Sleep)的进程。平均负载其实就是单位时间内的活跃进程数
平均负载多少时合理?
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 最理想的状态是每个CPU上都刚还运行着一个进程,这样每个CPU都得到了充分利用。 所以在评判负载时,首先你要知道系统有几个CPU,这可以通过top命令获取,或grep 'model name' /proc/cpuinfo [root@localhost ~]# top [root@localhost ~]# cat /proc/cpuinfo [root@localhost ~]# lscpu 假设现在在4,2,1核的CPU上,如果平均负载为2时,意味着什么呢? 1.在4个CPU的系统上,意味着CPU有50%空闲。 2.在2个CPU的系统上,以为这所有的CPU都刚好完全被占用。 3.在1个CPU的系统上,则意味着有一半的进程竞争不到CPU。 1)三个值,不能只关注其中一个值(三个都要看) 2)不能根据1分钟负载低情况来判断,当前负载处于下降状态(不关注服务器的问题) 假设我们在有2个CPU系统上看到平均负载为2.73,6.90,12.98那么说明在过去1分钟内,系统有136%的超载 1分钟:(2.73/2*100%=136%) 5分钟:(6.90/2*100%=345%) 15分钟:(12.98/2*100%=649%) 计算公式:(负载/核心数)*100%
负载过高排查
1 2 3 4 5 6 7 web01机器很卡,找出原因 stress (K8S)是Linux系统压力测试工具,这里我们用作异常进程模拟平均负载升高的场景 mpstat是多核CPU性能分析工具,用来实时检查每个CPU的性能指标,以及所有CPU的平均指标。 pidstat是一个常用的进程性能分析工具,用来实时查看进程的CPU,内存,IO,以及上下文切换等性能指标。
4.CPU对负载影响 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 [root@localhost ~]# yum intall -y sysstat [root@localhost ~]# mpstat -P ALL 1 [root@localhost ~]# top %Cpu0 : 99.2 us, 0.0 sy, 0.0 ni, 0.0 id , 0.0 wa, 0.0 hi, 0.8 si, 0.0 st %Cpu1 :100.0 us, 0.0 sy, 0.0 ni, 0.0 id , 0.0 wa, 0.0 hi, 0.0 si, 0.0 st %Cpu2 : 0.0 us, 0.0 sy, 0.0 ni, 99.0 id , 0.0 wa, 0.0 hi, 1.0 si, 0.0 st %Cpu3 :100.0 us, 0.0 sy, 0.0 ni, 0.0 id , 0.0 wa, 0.0 hi, 0.0 si, 0.0 st [root@localhost ~]# pidstat -u 5 1 Linux 3.10.0-957.el7.x86_64 (localhost.localdomain) 04/26/2024 _x86_64_(4 CPU) 08:21:50 PM UID PID %usr %system %guest %CPU CPU Command 08:21:55 PM 0 9 0.00 0.20 0.00 0.20 0 rcu_sched 08:21:55 PM 0 60 0.00 0.20 0.00 0.20 0 kworker/0:1 08:21:55 PM 0 6618 0.00 0.20 0.00 0.20 0 sshd 08:21:55 PM 0 6803 99.60 0.20 0.00 99.80 3 java 08:21:55 PM 0 6804 99.40 0.40 0.00 99.80 2 java 08:21:55 PM 0 6805 99.60 0.40 0.00 100.00 1 java 08:21:55 PM 0 6815 0.00 0.20 0.00 0.20 0 pidstat Average: UID PID %usr %system %guest %CPU CPU Command Average: 0 9 0.00 0.20 0.00 0.20 - rcu_sched Average: 0 60 0.00 0.20 0.00 0.20 - kworker/0:1 Average: 0 6618 0.00 0.20 0.00 0.20 - sshd Average: 0 6803 99.60 0.20 0.00 99.80 - java Average: 0 6804 99.40 0.40 0.00 99.80 - java Average: 0 6805 99.60 0.40 0.00 100.00 - java Average: 0 6815 0.00 0.20 0.00 0.20 - pidstat tail -f /var/log/nginx/access.logtial -f /var/log/java/xxxx.log error:找到报错
5.磁盘IO对负载影响 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 [root@localhost ~]# mpstat -P ALL 3 Linux 3.10.0-957.el7.x86_64 (localhost.localdomain) 04/26/2024 _x86_64_(4 CPU) 08:29:48 PM CPU %usr %nice %sys %iowait %irq %soft %steal %guest %gnice %idle 08:29:51 PM all 0.17 0.00 73.85 0.00 0.00 0.00 0.00 0.00 0.00 25.98 08:29:51 PM 0 0.00 0.00 66.93 0.00 0.00 0.00 0.00 0.00 0.00 33.07 08:29:51 PM 1 0.00 0.00 68.15 0.00 0.00 0.00 0.00 0.00 0.00 31.85 08:29:51 PM 2 0.00 0.00 79.87 0.00 0.00 0.00 0.00 0.00 0.00 20.13 08:29:51 PM 3 0.00 0.00 78.92 0.00 0.00 0.00 0.00 0.00 0.00 21.08 [root@localhost ~]# iostat Linux 3.10.0-957.el7.x86_64 (localhost.localdomain) 04/26/2024 _x86_64_(4 CPU) avg-cpu: %user %nice %system %iowait %steal %idle 16.40 0.00 3.49 0.01 0.00 80.10 Device: tps kB_read/s kB_wrtn/s kB_read kB_wrtn scd0 0.01 0.53 0.00 1028 0 sda 6.23 283.56 8.79 548598 17015 [root@localhost ~]# pidstat -u 5 1 08:30:36 PM 0 6831 0.40 76.74 0.00 77.14 3 stress 08:30:36 PM 0 6832 0.00 78.13 0.00 78.13 1 stress 08:30:36 PM 0 6833 0.00 74.55 0.00 74.55 3 stress
6.多进程对负载影响 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 [root@localhost ~]# mpstat -P ALL 3 Linux 3.10.0-957.el7.x86_64 (localhost.localdomain) 04/26/2024 _x86_64_(4 CPU) 08:33:45 PM CPU %usr %nice %sys %iowait %irq %soft %steal %guest %gnice %idle 08:33:48 PM all 53.94 0.00 0.25 0.00 0.00 0.25 0.00 0.00 0.00 45.57 08:33:48 PM 0 53.00 0.00 0.50 0.00 0.00 0.00 0.00 0.00 0.00 46.50 08:33:48 PM 1 54.41 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00 45.59 08:33:48 PM 2 52.50 0.00 0.50 0.00 0.00 0.50 0.00 0.00 0.00 46.50 08:33:48 PM 3 55.02 0.00 0.00 0.00 0.00 0.48 0.00 0.00 0.00 44.50 [root@localhost ~]# pidstat -u 5 1 08:30:36 PM 0 6831 0.40 76.74 0.00 77.14 3 stress 08:30:36 PM 0 6832 0.00 78.13 0.00 78.13 1 stress 08:30:36 PM 0 6833 0.00 74.55 0.00 74.55 3 stress 1.平均负载高有可能是CPU密集型进程导致的 2.平均负载高并不一定代表CPU的使用率就一定高,还有可能是I/O繁忙 3.当发现负载高时,可以使用mpstat、pidstat等工具,快速定位到,负载高的原因,从而做出处理
负载达到多少时候需要注意
1 2 当平均负载高于CPU数量70%的时候,你就应该分析排查负载高的问题了,一旦负载过高,就可能导致进程相应变慢,进而影响服务的正常功能。 但70%这个数字并不是绝对的,最推荐的方法,还是把系统的平均负载监控起来,然后根据更多的历史数据,判断负载的变化趋势,当发现负载有明显升高的趋势时,比如说负载翻倍了,你再去做分析和调查。
3.系统启动流程 1.Centos6启动流程 ==1.加电自检==
1 2 3 4 5 6 7 8 Centos6 1.BIOS加电自检 2.内核引导 3.读取GRUB菜单 4.运行init,读取/etc/inittab默认运行级别 5.按顺序启动其他服务/etc/rcN.d 6.建立终端 7.用户登录
==2.内核引导==
1 2 3 4 打开电源,BiOS加电自检 检测硬件是否损坏:CPU、内存、磁盘 读取/boot目录下的文件,加载启动文件,GRUB菜单 GRUB菜单提供已安装系统的选项,如果是多系统,选择要进入的系统
==3.运行init==
init运行级别 init 在CentOS中,是系统所有进程的起点,如果进程想启动,那必须有init,如果没有init,系统中的任 何进程都不会启动,那就相当于这个系统打不开
1 2 3 4 5 6 7 8 9 10 init是CentOS6中PID为0的进程,是所有进程启动的起点 [root@localhost ~]# pstree init─┬─abrtd ├─acpid ├─atd ├─auditd───{auditd} ├─console-kit-dae───63*[{console-kit-da}] ├─sshd───sshd───bash───pstree └─udevd───2*[udevd]
==运行级别==
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 init程序首先是需要读取配置文件/etc/inittab [root@localhost ~]# cat /etc/inittab id :3:initdefault: 0:关机运行级别 1:单用户模式运行级别 2:多用户模式,但是没有文件系统,没有网络 3:完整的多用户模式,有文件系统,有网络 4:未被使用的运行级别 5:图形化运行级别 6:重启运行级别
==查看当前运行级别==
1 2 3 4 5 6 7 [root@localhost ~]# runlevel N 3 [root@localhost ~]# init 5 [rootezls ~]vim /etc/inittab id :3:initdefault
读取完配置文件,找到对应的运行级别 3
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 查询操作系统在每一个执行等级中会执行哪些系统服务,其中包括各类常驻服务。 [root@localhost ~]# chkconfig [root@localhost ~]# chkconfig |grep '3:on' auditd 0:off 1:off 2:on 3:on 4:on 5:on 6:off crond 0:off 1:off 2:on 3:on 4:on 5:on 6:off ip6tables 0:off 1:off 2:on 3:on 4:on 5:on 6:off iptables 0:off 1:off 2:on 3:on 4:on 5:on 6:off kdump 0:off 1:off 2:off 3:on 4:on 5:on 6:off mdmonitor 0:off 1:off 2:on 3:on 4:on 5:on 6:off netfs 0:off 1:off 2:off 3:on 4:on 5:on 6:off network 0:off 1:off 2:on 3:on 4:on 5:on 6:off postfix 0:off 1:off 2:on 3:on 4:on 5:on 6:off rsyslog 0:off 1:off 2:on 3:on 4:on 5:on 6:off sshd 0:off 1:off 2:on 3:on 4:on 5:on 6:off udev-post 0:off 1:on 2:on 3:on 4:on 5:on 6:off
==5.系统初始化==
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 [root@localhost ~]# ll /etc/rc3.d/ total 0 lrwxrwxrwx. 1 root root 19 Apr 29 17:06 K10saslauthd -> ../init.d/saslauthd lrwxrwxrwx. 1 root root 21 Apr 29 17:06 K87restorecond -> ../init.d/restorecond lrwxrwxrwx. 1 root root 20 Apr 29 17:06 K89netconsole -> ../init.d/netconsole lrwxrwxrwx. 1 root root 15 Apr 29 17:06 K89rdisc -> ../init.d/rdisc lrwxrwxrwx. 1 root root 19 Apr 29 17:06 S08ip6tables -> ../init.d/ip6tables lrwxrwxrwx. 1 root root 18 Apr 29 17:06 S08iptables -> ../init.d/iptables lrwxrwxrwx. 1 root root 17 Apr 29 17:06 S10network -> ../init.d/network lrwxrwxrwx. 1 root root 16 Apr 29 17:07 S11auditd -> ../init.d/auditd lrwxrwxrwx. 1 root root 17 Apr 29 17:06 S12rsyslog -> ../init.d/rsyslog lrwxrwxrwx. 1 root root 19 Apr 29 17:06 S15mdmonitor -> ../init.d/mdmonitor lrwxrwxrwx. 1 root root 15 Apr 29 17:06 S25netfs -> ../init.d/netfs lrwxrwxrwx. 1 root root 19 Apr 29 17:06 S26udev-post -> ../init.d/udev-post lrwxrwxrwx. 1 root root 15 Apr 29 17:07 S50kdump -> ../init.d/kdump lrwxrwxrwx. 1 root root 14 Apr 29 17:07 S55sshd -> ../init.d/sshd lrwxrwxrwx. 1 root root 17 Apr 29 17:06 S80postfix -> ../init.d/postfix lrwxrwxrwx. 1 root root 15 Apr 29 17:06 S90crond -> ../init.d/crond lrwxrwxrwx. 1 root root 11 Apr 29 17:06 S99local -> ../rc.local [root@localhost ~]# ll /etc/init.d/ 查看所有程序的启动脚本 [root@localhost ~]# cat /etc/init.d/sshd 在2345运行级别上,默认开机自启 55:开机第55个启动 25:关机第25个关闭
==6.建立终端==
1 2 3 4 5 6 7 8 9 10 rc执行完毕后,返回init。这时基本系统环境已经设置好了,各种守护进程也已经启动了。 init接下来会打开6个终端,以便用户登录系统。在inittab中的以下6行就是定义了6个终端: 1:2345:respawn:/sbin/mingetty tty1 2:2345:respawn:/sbin/mingetty tty2 3:2345:respawn:/sbin/mingetty tty3 4:2345:respawn:/sbin/mingetty tty4 5:2345:respawn:/sbin/mingetty tty5 6:2345:respawn:/sbin/mingetty tty6 远程连接工具 pts/0
==7.用户登录系统==
一般来说,用户的登录方式有三种:
1 2 3 (1)命令行登录 (2)ssh登录 (3)图形界面登录
2.系统关机命令 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 halt shutdown -h now poweroff sync 将数据由内存同步到硬盘中。shutdown 关机指令 shutdown –h 10 shutdown –h now shutdown –h 20:25 shutdown –h +10 shutdown –r now shutdown –r +10 reboot halt reboot init 6
3.单用户模式 ==忘记密码进入单用户模式改密码==
1)重启系统,到grub菜单界面
2)回车返回内核菜单
3)进入后就可以重新设置密码了
密码设置好重启就OK了
reboot init6
4.CentOS7启动顺序 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 1.BIOS(开机自检) 2.MBR ( Master Boot Record 主引导记录) 3.GRUB2 Bootloader(引导菜单) 4.Kernel(内核引导) 5.Systemd (不再使用init,改成了systemd) 6.按顺序启动其他服务 systemctl list-unit-files [root@lb01 ~]# systemctl list-unit-files UNIT FILE STATE proc-sys-fs-binfmt_misc.automount static dev-hugepages.mount static dev-mqueue.mount static proc-sys-fs-binfmt_misc.mount static sys-fs-fuse-connections.mount static sys-kernel-config.mount static sys-kernel-debug.mount static 7.建立终端 8.用户登录 /usr/lib/systemd/system/runlevel0.target -> poweroff.target /usr/lib/systemd/system/runlevel1.target -> rescue.target /usr/lib/systemd/system/runlevel2.target -> multi-user.target /usr/lib/systemd/system/runlevel3.target -> multi-user.target /usr/lib/systemd/system/runlevel4.target -> multi-user.target /usr/lib/systemd/system/runlevel5.target -> graphical.target /usr/lib/systemd/system/runlevel6.target -> reboot.target 0:关机运行级别 (Do NOT set initdefault to this) 1:单用户模式运行级别 2,3,4:完整的多用户模式,有文件系统,有网络 5:图形化运行级别 6:重启运行级别 (Do NOT set initdefault to this) [root@yum_repo ~]# systemctl get-default [root@localhost ~]# systemctl list-unit-files|grep 'enabled' /usr/lib/systemd/system/ [root@yum_repo ~]# systemctl set-default multi-user.target [root@localhost ~]# ll /etc/systemd/system/multi-user.target.wants/ auditd.service -> /usr/lib/systemd/system/auditd.service nginx.service -> /usr/lib/systemd/system/nginx.service firewalld.service -> /usr/lib/systemd/system/firewalld.service irqbalance.service -> /usr/lib/systemd/system/irqbalance.service NetworkManager.service -> /usr/lib/systemd/system/NetworkManager.service postfix.service -> /usr/lib/systemd/system/postfix.service remote-fs.target -> /usr/lib/systemd/system/remote-fs.target rhel-configure.service -> /usr/lib/systemd/system/rhel-configure.service rsyslog.service -> /usr/lib/systemd/system/rsyslog.service sshd.service -> /usr/lib/systemd/system/sshd.service tuned.service -> /usr/lib/systemd/system/tuned.service vmtoolsd.service -> /usr/lib/systemd/system/vmtoolsd.service
5.CentOS7单用户模式 1.重启系统
2.进入grub2菜单
1 2 3 enforcing=0 init=/bin/bash enforcing=0 关闭selinux(临时的),进入单用户后配置文件里关闭selinux,否则重新开机后密码就不生效了
不挂载方式
3.进入单用户模式
1 2 3 4 5 6 mount -o rw,remount / passwd root exec /sbin/init
1 2 3 4 5 6 7 8 进入配置文件永久关闭selinux [root@lb01 ~]# vi /etc/selinux/config SELINUX=disabled 将permissive改为disabled SELINUXTYPE=targeted 查看selinux开启状态 [root@lb01 ~]# getenforce Disabled
6.修改默认运行级别 如果centos7被设置为运行级别6,导致无限重启怎么解决?
1 2 3 4 5 [root@yum_repo ~]# systemctl get-default multi-user.target [root@yum_repo ~]# systemctl set-default reboot.target
解决办法
1.进入编辑模式
2.#在linux16行的末尾输入,然后按下 Ctrl+X 组合键来运行修改过的内核程序
exit退出,reboot重启
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 mount -o rw,remount /sysroot chroot /sysrootpasswd root systemctl set-default multi-user.target exit reboot [root@yum_repo ~]# setenforce 0 [root@yum_repo ~]# vi /etc/sysconfig/selinux SELINUX=disabled 1)enforcing=0 init=/bin/bash // 修改密码 2)rd.break // 修改运行级别
4.救援模式 前提:虚拟机设置已经挂载iso镜像
1.MBR引导被破坏解决 1 2 dd < /dev/zero >/dev/sda bs=1 count=446
1 2 3 4 5 6 7 8 9 10 chroot /mnt/sysimagegrub2-install /dev/sda exit reboo 过程如下↓
MBR破坏后启动自动跳到这里
进入救援模式前进入BISO,修改优先CD-ROM启动加载
2.grub菜单误删解决 1 2 3 [root@lb01 ~]# rm -fr /boot/grub2 [root@lb01 ~]# reboot
解决过程
1 2 3 4 5 6 7 8 9 10 11 chroot /mnt/sysimagegrub2-install /dev/sda grub2-mkconfig -o /boot/grub2/grub.cfg exit reboot 过程图如下
grub菜单被删启动界面
同样进入救援模式
3.系统损坏拷贝文件 1 2 3 4 5 bash-4.2# mkfs.xfs -f /dev/sdc bash-4.2# mkdir /data bash-4.2# mount /dev/sdc /data bash-4.2# cp -a /raid0 /data bash-4.2# umount /dev/sdb
5.Systemd 进程管理 1 systemd即为system daemon守护进程,systemd主要解决上文的问题而诞生,systemd的目标是,为系统的启动和管理提供一套完整的解决方案。
1 2 3 4 5 1.启动时间长,init进程是串行启动,只有前一个进程启动完,才会启动下一个进程。 2.启动脚本复杂,初始化完成后,系统会加载很多脚本,脚本都会处理各自的情况,这回让脚本多而复杂。 CtOS7所有进程无论有无依赖关系,都并行启动,当然有很多时候进程并没有真正的启动而是只有一个信号或者说是标记,在真正利用的时候,才会真正启动
1 2 3 4 5 6 1.最新系统都采用systemd管理(RedHat7,CentOS7,Ubuntu15...) 2.CentOS7 支持开机并行启动服务,显著提高开机启动效率 3.CentOS7关机只关闭正在运行的服务,而CentOS6,全部都关闭一次。 4.CentOS7服务的启动与停止不在使用脚本进行管理,也就是/etc/init.d下不在有脚本。 5.CentOS7使用systemd解决原有模式缺陷,比如原有service不会关闭程序产生的子进程。
相关配置文件
CentOS6
CentOS7
服务启动脚本
/etc/init.d/
/usr/lib/systemd/system/
开机启动服务
/etc/rcN.d/
/etc/systemd/system/
systemd相关命令 启动重启服务
System V init(6系统)
systemctl命令(7系统)
作用
service nginx start
systemctl start nginx.service
启动服务
service nginx stop
systemctl stop nginx.service
停止服务
service nginx restart
systemctl restart nginx.service
重启服务
service nginx reload
systemctl reload nginx.service
重新加载配置(不终止服务)
service nginx status
systemctl status nginx.servre
查看服务运行状态
systemctl is-active sshd.service
查看服务是否在运行中
systemctl mask nginx.servre
禁止服务运行
systemctl unmask nginx.servre
取消禁止服务运行
设置服务开机自启,查看各级别下服务启动状态
System V init(6系 统)
systemctl命令(7系统)
作用
chkconfig nginx on
systemctl enable nginx.service
开机自动启动
chkconfig nginx off
systemctl disable nginx.service
开机不自动启动
chkconfig —list
systemctl list-unit-files
查看各个级别下服务的启动与禁 用
chkconfig —list nginx
systemctl is-enabled nginx.service
查看特定服务是否为开机自启动
chkconfig—add nginx
systemctl daemon-reload
创建新服务文件或者变更设置
1 2 3 4 5 6 7 8 设置开机自启相当于给启动脚本做个软链接 [root@localhost ~]# systemctl enable sshd ln -s /usr/lib/systemd/system/sshd.service /etc/systemd/system/multiuser.target.wants/[root@localhost ~]# systemctl disable sshd Removed symlink /etc/systemd/system/multi-user.target.wants/sshd.service rm -f /etc/systemd/system/multi-user.target.wants/sshd.service
systemctl服务状态说明
服务状态
状态说明
loaded
服务单元的配置文件已经被处理
active(running)
服务的一个或多个进程在运行中
active(exited)
一次性运行的服务成功被执行并退出(服务运行后完成任务,相关进程会自动退出)
active(waiting)
服务已经运行但在等待某个事件
inactive
服务没有在运行
enable
服务设定为开机运行
disabled
服务设定为开机不运行
static
服务不能被设定开机启动,但可以由其他服务启动该服务
6.定时任务 1 2 3 4 5 crond就是计划任务,类似于我们平时生活中的闹钟,定点执行。 [root@localhost ~]# ps aux|grep crond root 6349 0.0 0.1 126284 1612 ? Ss 16:00 0:00 /usr/sbin/crond -n
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 [root@lb01 ~]# free -m(以m显示内存多少) 总内存 已使用 空闲 可使用内存 total used free shared buff/cache available Mem: 972 89 760 7 123 737 Swap: 1023 0 1023 [root@localhost ~]# free 总内存 已使用 空闲 total used free shared buffers cached Mem: 1004768 170984 833784 220 13336 48440 -/+ buffers/cache: 109208 895560(可使用内存) Swap: 1048572 0 1048572 总内存:free -m|awk '/^Mem/{print $2}' 已使用内存:free -m|awk '/^Mem/{print $3}' 可用内存:free -m|awk '/^Mem/{print $NF}' mem_total=`free -m|awk '/^Mem/{print $2}' ` mem_used=`free -m|awk '/^Mem/{print $3}' ` mem_ava=`free -m|awk '/^Mem/{print $NF}' ` echo "------ 内存信息 ------" echo "总内存:${mem_total} M" echo "已使用内存:${mem_used} M" echo "可用内存:${mem_ava} M"
1.定时任务语法 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 [root@localhost ~]# cat /etc/crontab SHELL=/bin/bash PATH=/sbin:/bin:/usr/sbin:/usr/bin MAILTO=root sun,mon,tue,wed,thu,fri,sat [root@localhost ~]# echo $PATH /usr/local/sbin:/usr/local/bin:/usr/sbin:/usr/bin:/root/bin * * * * * [用户] 可执行的命令 分 时 日 月 周 00 02 * * * ls 00 02 1 * * ls 00 02 14 2 * ls 00 02 * * 7 ls 00 02 * 6 5 ls 00 02 14 * 7 ls 00 02 14 2 7 ls */10 02 * * * ls * * * * * ls */1 * * * * ls 00 00 14 2 * ls */5 * * * * ls 00 02 * 1,5,8 * ls 00 02 1-8 * * ls 0 21 * * * ls * 21 * * * ls 45 4 1,10,22 * * ls 45 4 1-10 * * ls 3,15 8-11 */2 * * ls 0 23-7/1 * * * ls 15 21 * * 1-5 ls
2.crontab命令选项 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 -e:edit 编辑 -l:查看当前登录用户都有哪些定时任务 -u:指定用户查看定时任务 -r:清空所有定时任务 [root@localhost ~]# crontab -e * * * * * /usr/sbin/ntpdate ntp1.aliyun.com &>/dev/null 1)命令绝对路径 2)输出定向到空 3)定时任务加注释 [root@web01 /]# cd / && tar zcf /tmp/$(date +%F)_$(hostname -s)_etc.tar.gz etc [root@web01 ~]# vi /opt/backup.sh cd / && tar zcf /tmp/$(date +%F)_$(hostname -s)_etc.tar.gz etc[root@lb01 ~]# tail -f /var/log/cron [root@localhost ~]# date +%F-%H:%M:%S 2024-05-13-17:35:25 %F:年月日 %Y:year 年 %m:mouth 月 %d:day 日 %H:hour时 %M:minute分 %S:seconds秒 %A:星期 %w:星期(阿拉伯数字显示)
3.crontab注意事项 1 2 3 4 5 1) 给定时任务注释 2) 将需要定期执行的任务写入Shell脚本中,避免直接使用命令无法执行的情况tar date 3) 定时任务的结尾一定要有&>/dev/null或者将结果追加重定向>>/tmp/date.log文件 4) 注意有些命令是无法成功执行的 echo "123" >>/tmp/test.log &>/dev/null 5.如果一定要是用命令,命令必须使用绝对路径
4.定时任务—-做备份 1 2 3 4 5 6 7 [root@web01 ~]# ll /var/spool/cron/ total 8 -rw------- 1 root root 165 May 6 11:32 root -rw------- 1 zls zls 27 May 6 2024 zls [root@web01 ~]# echo 'username' > /etc/cron.deny
5.计划任务调试思路 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 1.crond调试 1) 调整任务每分钟执行的频率, 以便做后续的调试。 2) 如果使用cron运行脚本,请将脚本执行的结果写入指定日志文件, 观察日志内容是否正常。 3) 命令使用绝对路径, 防止无法找到命令导致定时任务执行产生故障。 4) 通过查看/var/log/cron日志,以便检查我们执行的结果,方便进行调试。 2.crond编写思路 1.手动执行命令,然后保留执行成功的结果。 2.编写脚本 脚本需要统一路径/scripts 脚本内容复制执行成功的命令(减少每个环节出错几率) 脚本内容尽可能的优化, 使用一些变量或使用简单的判断语句 脚本执行的输出信息可以重定向至其他位置保留或写入/dev/null 3.执行脚本 使用bash命令执行, 防止脚本没有增加执行权限(/usr/bin/bash) 执行脚本成功后,复制该执行的命令,以便写入cron 4.编写计划任务 加上必要的注释信息, 人、时间、任务 设定计划任务执行的周期 粘贴执行脚本的命令(不要手敲) 5.调试计划任务 增加任务频率测试 检查环境变量问题 检查crond服务日志
6.使用定时任务发邮件 配置邮箱
1 2 3 4 5 6 7 8 9 10 11 12 [root@web01 ~]# yum install -y mailx [root@web01 ~]# vi /etc/mail.rc set from=邮箱 set smtp=smtps://smtp.qq.com:465 set smtp-auth-user=邮箱 set smtp-auth-password=客户端授权码 set smtp-auth=loginset ssl-verify=ignoreset nss-config-dir=/etc/pki/nssdb/
邮箱生成授权码
发邮件
1 2 3 [root@web01 ~]# echo '邮件内容' |mail -s '邮件标题' 3078155561@qq.com [root@web01 ~]# cat /etc/passwd|mail -s 'test' 3078155561@qq.com cat /root/backup.log.txt|mail -s '备份文件' 3078155561@qq.com
7.定时任务实例 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 需求:将备份命令写入一个脚本中 1.每天备份文件名要求格式:2018-0220_hostname_etc.tar.gz 2.存放备份内容的目录要求只保留3天的数据 3.在执行计划任务时,不要输出任务信息 4.备份是否成功结果,发送邮件 备份时间:精确到秒 备份文件名:2024-05-06_web01_etc.tar.gz 备份路径:/tmp 是否成功: vim backup.sh find /etc/* -type d -mtime -3|xargs tar zcf /tmp/$(date +%F)_$(hostname -s)_etc.tar.gz echo "备份时间:$(date +%Y/%m/%d\ %H:%M:%S) " >>backuplog.txtecho "备份文件名:$(date +%F) _$(hostname -s) _etc.tar.gz" >>backuplog.txtecho "备份路径:/tmp" >>backuplog.txtecho "是否备份成功:是" >>backuplog.txt[root@lb01 ~]# crontab -e 0 23 * * * /usr/bin/sh backup.sh &>/dev/null 0 00 * * * /usr/bin/cat /root/backup.log.txt|mail -s '备份文件' 3078155561@qq.com
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 需求:将备份命令写入一个脚本中 任务: 1.每天备份文件名要求格式:2018-02-20_hostname_etc.tar.gz 2.存放备份内容的目录要求只保留3天的数据 3.在执行计划任务时,不要输出任务信息 4.备份是否成功结果,发送邮件 备份文件名:2024-05-06_web01_etc.tar.gz 备份路径:/tmp 是否成功: cd / && tar zcf $(date +%F)_$(hostname -s)_etc.tar.gzfind /etc/* -type d -mtime -3 tar zcf /tmp/$(date +%F)_$(hostname -s)_etc.tar.gz /etc/* find /etc/* -type d -mtime -3|xargs tar zcf /tmp/$(date +%F)_$(hostname -s)_etc.tar.gz
7.修改网卡名
1 2 biosdevname=0 net.ifnames=0 net.ifnames=0
【9】三剑客 正则表达式 1. 正则符号
分类
基础正则 Basic RE (BRE)
^ $ ^$ . . [a-z] abc
扩展正则 Extended RE (ERE)
+ \
() ?
扩展正则
符号
作用
+
前一个字连续出现1次或者1次以上
\
表示或者
()
()里面的内容可以看成是一个整体
{}
指定出现的次数
?
前一个字符出现了0次或1次
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 [a-z]+ 匹配连续出现的单词,贪婪匹配 [0-9]+ 匹配连续出现的数字,贪婪匹配 过滤出oldboy或者oldbey [root@lb01 ~s]#egrep 'oldb(o|e)y' oldboy.txt [root@lb01 ~s]#egrep 'oldb[oe]y' oldboy.txt 0{m,n} 0至少出现m次,至多出现n次 0{3}0出现了3次 0{m,}0至少出现m次,最多出现次数不限 0{,n}0至多出现n次,最少出现次数不限 [root@lb01 ~s]#egrep 'go?d' oldboy.txt god gd
2.正则&通配符
分类
用途
支持的命令
正则(re)
三剑客,高级语言,进行过滤(匹配字符)
三剑客grep sed,awk,find,rename,expr
通配符(pathname extension 或 glob)
匹配文件/文件名 *.txt
linux下大部分都支持
三剑客
命令
特点
场景
grep
过滤
grep命令过滤速度是最快的
sed
替换,修改文件内容,取行
如果要进行替换/修改文件内容取
awk
取列,统计
取列,对比,比较
grep专区
选项
作用
-n
显示行号
-A
After 过滤关键字并打印出后N行
-B
Before 过滤关键字并打印出前N行
-C
Center 过滤关键字并打印出前后N行
-v
取反
-o
只显示关键字内容
-i
忽略大小写
-w
精确匹配
-c
相当于count,用于统计行数
-r/-R
递归搜索目录及目录下得文件
字符
关键字可以使用的符号
作用
^
以……开头 abc\
$
以……结尾 ^$可以表示空行
.
任意一个字符
*
*号前面的单个字符匹配0次或多次
\
正则表达式里面或者意思,grep默认不支持正则表达式,需要用-E
\b
边界符 例:\boldboy\b
注意:[]里的内容一般都会去掉特殊含义,做自己
转义字符 \
\n 回车换行
\t tab键
1 2 3 4 5 6 7 8 9 10 11 12 awk '/K.*D/ {print $6}' /K.*D/这是搜索A开头D开头的字符 如果搜索内容里面含有/,需要使用转义符,例如awk '/\/sbin\/nologin/ {print $6}' grep -r逐级搜索 [root@lb01 ~]# grep -r 'K.*D' /root /root/11.txt:47 Oct 3ZL1998 LPSX 43.00 KVM9D 512 /root/11.txt:483 may 5PA1998 USP 37.00 KVM9D 644 grep -rl只显示文件名 [root@lb01 ~]# grep -rl 'K.*D' /root /root/anaconda-ks.cfg /root/11.txt
grep专区
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 KabcD 过滤K开头D结尾的内容 .*代表任意字符 [root@lb02 ~]# grep 'K.*D' 1.txt 过滤至少以一个空白字符开头的行,+代表贪婪匹配 [root@lb02 ~]# grep -E '^[ ]+' 1.txt 过滤以a或者b开头的行 1.[root@lb02 ~]# grep '^[ab]' 1.txt 2.[root@lb02 ~]# grep -E '^(a|b)' 1.txt grep -E '^a|^b' 1.txt 过滤a11ab类型的内容(字母 数字 数字 字母 字母) [root@lb02 ~]# grep -E '[a-z][0-9][0-9][a-z][a-z]' 1.txt [root@lb02 ~]# grep -E '[a-z][0-9]{2}[a-z]{2}' 1.txt {2}表示前面的出现了2次 过滤 字母开头且后面跟至少2个到4个数字的内容 [root@lb02 ~]# grep -Eo '^[a-z][0-9]{2,4}' 1.txt a11 b1232 0-9、 10-99、 100-199、 200-249、 250-255 [0-9] [1-9][0-9] 1[0-9][0-9] 2[0-4][0-9] 25[0-5] 过滤非字母开头的内容 [root@lb02 ~]# grep '^[^a-zA-Z]' 1.txt
| 和[ ]表或者的区别
符合
区别
\
1次匹配1个字符 [abc] ==> 或者a或者b或者c
[ ]
匹配1个或多个字符 a\
b\
c abc\
bcd
( )使用
被括起来的内容,表示一个整体(一个字符)
后向引用(反向引用sed)
sed命令 1 2 3 4 5 6 7 8 9 10 11 作用: 1.模糊过滤文件的内容 2.查找指定的行 3.对文件进行增删改查 4.替换 5.格式化输出内容,后向引用 sed 语法格式: grep '过滤内容' 文件 sed '/过滤内容/' 文件 sed '模式 动作' 文件 sed '找谁 干啥' 文件
功能
s
替换substitute
p
显示print
d
删除delete
cai
增加c/a/i
sed-查找p
‘2p’
指定行号进行查找
‘1,5p’
指定行号范围查找
‘/oldboy/p’
类似于grep过滤,//里面可以写正则
‘/10:00/,/11:00/p’
表示范围的过滤
==查找显示==
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 语法格式: sed -n '3p' 文件 cat 文件|sed -n '3p' [root@db01 ~]# head -5 /etc/passwd > test.txt [root@db01 ~]# sed -n '3p' test.txt [root@db01 ~]# sed -n '$p' test.txt lp:x:4:7:lp:/var/spool/lpd:/sbin/nologin [root@db01 ~]# sed -n '2,4p' test.txt bin:x:1:1:bin:/bin:/sbin/nologin daemon:x:2:2:daemon:/sbin:/sbin/nologin adm:x:3:4:adm:/var/adm:/sbin/nologin [root@db01 ~]# sed -n '2,$p' test.txt bin:x:1:1:bin:/bin:/sbin/nologin daemon:x:2:2:daemon:/sbin:/sbin/nologin adm:x:3:4:adm:/var/adm:/sbin/nologin lp:x:4:7:lp:/var/spool/lpd:/sbin/nologin [root@db01 ~]# ifconfig eth0|sed -n '2p' inet 10.0.0.200 netmask 255.255.255.0 broadcast 10.0.0.255
==过滤==
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 语法结构: sed -n '/过滤的内容/p' file [root@db01 ~]# sed -n '/root/p' test.txt root:x:0:0:root:/root:/bin/bash 使用正则: [root@db01 ~]# sed -n '/^r/p' test.txt root:x:0:0:root:/root:/bin/bash 过滤以a或b或c开头的行 [root@db01 ~]# sed -n '/^[a-c]/p' test.txt bin:x:1:1:bin:/bin:/sbin/nologin adm:x:3:4:adm:/var/adm:/sbin/nologin 过滤以什么结尾的行 [root@db01 ~]# sed -n '/h$/p' test.txt root:x:0:0:root:/root:/bin/bash [root@db01 ~]# sed -n '/n$/p' test.txt bin:x:1:1:bin:/bin:/sbin/nologin daemon:x:2:2:daemon:/sbin:/sbin/nologin adm:x:3:4:adm:/var/adm:/sbin/nologin lp:x:4:7:lp:/var/spool/lpd:/sbin/nologin 过滤区间范围: sed -n '//,//p' 文件 sed -n '2,4p' 文件 过滤字符串区间范围: [root@db01 ~]# sed -n '/^bin/,/^a/p' test.txt bin:x:1:1:bin:/bin:/sbin/nologin daemon:x:2:2:daemon:/sbin:/sbin/nologin adm:x:3:4:adm:/var/adm:/sbin/nologin 案例: 过滤时间 统计上午8点到中午12点中间数据 [root@linuxnc ~]# sed -n '/2024:08:00:15/,/2024:09:30:42/p' /var/log/nginx/access.log 注意匹配方式: [root@db01 ~]# cat a.txt aaa bbb ccc bbb uuu ddd eee fff ddd xxx [root@db01 ~]# sed -n '/bbb/,/ddd/p' a.txt bbb ccc bbb uuu ddd
sed-删除d
‘1,5d’
指定行号范围查找
‘/oldboy/d’
类似于grep过滤,//里面可以写正则
‘2d’
指定行号进行查找
‘/10:00/,/11:00/d’
表示范围的过滤
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 指定行删除: 语法格式: sed '3d' file 修改源文件 sed -i '3d' file 案例1.删除文件的第3行 [root@db01 ~]# sed '3d' test.txt root:x:0:0:root:/root:/bin/bash bin:x:1:1:bin:/bin:/sbin/nologin lp:x:4:7:lp:/var/spool/lpd:/sbin/nologin 案例2.删除2到4行 [root@db01 ~]# sed '2,4d' test.txt root:x:0:0:root:/root:/bin/bash 案例3.删除2到最后一行 [root@db01 ~]# sed '2,$d' test.txt 模糊过滤内容,然后删除 语法结构: sed '/字符串/d' file 删除包含root的行 [root@db01 ~]# sed '/root/d' test.txt bin:x:1:1:bin:/bin:/sbin/nologin adm:x:3:4:adm:/var/adm:/sbin/nologin lp:x:4:7:lp:/var/spool/lpd:/sbin/nologin 删除b开头的行 [root@db01 ~]# sed '/^b/d' test.txt root:x:0:0:root:/root:/bin/bash adm:x:3:4:adm:/var/adm:/sbin/nologin lp:x:4:7:lp:/var/spool/lpd:/sbin/nologin -r 支持扩展正则 |或者的意思 [root@db01 ~]# sed -rn '/^bin|^p/p' test.txt bin:x:1:1:bin:/bin:/sbin/nologin p:x:4:7:lp:/var/spool/lpd:/sbin/nologin 删除bin开头或者lp开头的行 [root@db01 ~]# sed -r '/^bin|^lp/d' test.txt root:x:0:0:root:/root:/bin/bash adm:x:3:4:adm:/var/adm:/sbin/nologin 匹配区间范围进行删除: [root@db01 ~]# sed '/^bin/,/^adm/d' test.txt root:x:0:0:root:/root:/bin/bash lp:x:4:7:lp:/var/spool/lpd:/sbin/nologin sed -nr '/^&|#/!p' /etc/ssh/sshd_config 遇到空行和#行不显示
sed-增加
功能
含义
c
replace替代这一行
a
append追加,向指定的行或每一行插入内容(行后)
i
insert插入,向指定的行或每一行插入内容(行前)
w
将找到的内容保存到新文件内
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 sed '3a root' /text.txt 1. cat >>test.txt<<'EOF' abc cdf EOF 2. sed '$a abc\nsdf' test.txt 1. i 插入 在第3行前写入aaa [root@db01 ~]# sed '3i aaa' test.txt root:x:0:0:root:/root:/bin/bash bin:x:1:1:bin:/bin:/sbin/nologin aaa daemon:x:2:2:daemon:/sbin:/sbin/nologin adm:x:3:4:adm:/var/adm:/sbin/nologin root:x:0:0:root:/root:/bin/bash lp:x:4:7:lp:/var/spool/lpd:/sbin/nologin 2. a追加 在第3行的下一行 在第4行写入aaa [root@db01 ~]# sed '3a aaa' test.txt root:x:0:0:root:/root:/bin/bash bin:x:1:1:bin:/bin:/sbin/nologin daemon:x:2:2:daemon:/sbin:/sbin/nologin aaa adm:x:3:4:adm:/var/adm:/sbin/nologin root:x:0:0:root:/root:/bin/bash lp:x:4:7:lp:/var/spool/lpd:/sbin/nologin 3. c替换 替换整行内容 [root@db01 ~]# sed '3c aaa' test.txt root:x:0:0:root:/root:/bin/bash bin:x:1:1:bin:/bin:/sbin/nologin aaa adm:x:3:4:adm:/var/adm:/sbin/nologin root:x:0:0:root:/root:/bin/bash lp:x:4:7:lp:/var/spool/lpd:/sbin/nologin 替换第7行的内容关闭selinux [root@db01 ~]# sed -i '7c SELINUX=disabled' /etc/selinux/config 4. w 保存 将找到的行保存到新的文件中 [root@db01 ~]# sed '4w new.txt' test.txt 保存2到4行的内容到new.txt [root@db01 ~]# sed -n '2,4w new.txt' test.txt [root@db01 ~]# cat new.txt bin:x:1:1:bin:/bin:/sbin/nologin daemon:x:2:2:daemon:/sbin:/sbin/nologin adm:x:3:4:adm:/var/adm:/sbin/nologin
sed-替换s
1 2 3 4 5 6 7 8 1. 把每个单词的第一个小写字母变大写: sed 's/\b[a-z]/\u&/g' filename 2. 把所有小写变大写: sed 's/[a-z]/\u&/g' filename 3. 大写变小写: sed 's/[A-Z]/\l&/g' filename
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 88 89 90 91 92 93 94 95 96 97 语法结构: sed 's#将谁#替换成谁#g' 文件 sed 's@@@g' 文件 sed 's///g' 文件 案例: 只替换每行的第一个单词 root为oldboy [root@db01 ~]# sed 's#root#oldboy#' test.txt oldboy:x:0:0:root:/root:/bin/bash bin:x:1:1:bin:/bin:/sbin/nologin 案例: 替换所有的root为oldboy [root@db01 ~]# sed 's#root#oldboy#g' test.txt oldboy:x:0:0:oldboy:/oldboy:/bin/bash bin:x:1:1:bin:/bin:/sbin/nologin 案例: 将root替换成空 [root@db01 ~]# sed 's#root##g' test.txt :x:0:0::/:/bin/bash bin:x:1:1:bin:/bin:/sbin/nologin 案例: 删除所有的数字 [root@db01 ~]# sed 's#[0-9]##g' test.txt root:x:::root:/root:/bin/bash bin:x:::bin:/bin:/sbin/nologin 案例: 删除所有的字符串 [root@db01 ~]# sed 's#[a-z]##g' test.txt ::0:0::/:// ::1:1::/:// [root@db01 ~]# sed 's#[0-z]##g' test.txt :::::/:// :::::/:// 案例: 统计passwd中每个单词出现的次数 top10 将特殊符号替换成空 [root@db01 ~]# sed 's#[:/0-9x]# #g' test.txt root root root bin bash bin bin bin sbin nologin daemon daemon sbin sbin nologin adm adm var adm sbin nologin root root root bin bash lp lp var spool lpd sbin nologin [root@db01 ~]# sed 's#[:/0-9x]# #g' test.txt |xargs -n1|sort |uniq -c|sort -rn|head 6 root 5 sbin 5 bin 4 nologin 3 adm 2 var 2 lp 2 daemon 2 bash 1 spool 边界符: [root@db01 ~]# sed 's#\bbin\b#oldboy#g' test.txt 或者: [root@db01 ~]# sed 's#\<bin\>#oldboy#g' test.txt root:x:0:0:root:/root:/oldboy/bash oldboy:x:1:1:oldboy:/oldboy:/sbin/nologin 注意: 语法冲突需要使用撬棍\ 或者换个语法 [root@db01 ~]# sed 's/\/root/\/oldboy/g' test.txt 或者 [root@db01 ~]# sed 's#/root#/oldboy#g' test.txt 动作: sed -n '3p' 文件 sed 's###g' 文件 模式+动作 模式: 找谁,如何找 sed -n '3p' 演变: 将p输出动作 修改为替换动作 [root@db01 ~]# sed '3s#sbin#oldboy#g' test.txt 案例: 将2到4行的nologin替换成oldboy [root@db01 ~]# sed '2,4s#nologin#oldboy#g' test.txt bin:x:1:1:bin:/bin:/sbin/oldboy daemon:x:2:2:daemon:/sbin:/sbin/oldboy adm:x:3:4:adm:/var/adm:/sbin/oldboy lp:x:4:7:lp:/var/spool/lpd:/sbin/nologin [root@db01 ~]# sed '/adm/s#adm#oldboy#g' test.txt adm:x:3:4:adm:/var/adm:/sbin/oldboy ↓ ↘ ↘ oldboy:x:3:4:oldboy:/var/oldboy:/sbin/nologin 区间范围: [root@db01 ~]# sed '/adm/,/lp/s#[a-z]##g' test.txt root:x:0:0:root:/root:/bin/bash bin:x:1:1:bin:/bin:/sbin/nologin daemon:x:2:2:daemon:/sbin:/sbin/nologin ::3:4:://:// ::0:0::/:// ::4:7::///://
sed-后向引用 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 sed后向引用: 语法结构: sed s#()()()#\1\2\3#g -r支持扩展正则 [root@db01 ~]# echo oldboy|sed -r 's#(.*)#\1#g' oldboy [root@db01 ~]# [root@db01 ~]# echo oldboy|sed -r 's#ol(.*)oy#\1#g' db [root@db01 ~]# echo oldboy|sed -r 's#ol(.*)(oy)#\2#g' oy [root@db01 ~]# echo oldboy|sed -r 's#(ol)(.*)(oy)#\1#g' ol [root@db01 ~]# echo oldboy test |sed -r 's#(.*)#\1#g' oldboy test [root@db01 ~]# echo oldboy test |sed -r 's#(.*) test#\1#g' oldboy 案例: 取出IP地址 [root@db01 ~]# ifconfig eth0|sed -n '2p' |sed -r 's#^.*t (.*) netm.*$#\1#g' 10.0.0.200 第二种用法: 命令拼接后交给bash执行 [root@db01 ~]# seq 5|sed -r 's#(.*)#touch \1.txt#g' touch 1.txttouch 2.txttouch 3.txttouch 4.txttouch 5.txt[root@db01 ~]# seq 5|sed -r 's#(.*)#touch \1.txt#g' |bash -rw-r--r-- 1 root root 18 Mar 18 11:46 1.txt -rw-r--r-- 1 root root 0 Mar 18 11:46 2.txt -rw-r--r-- 1 root root 0 Mar 18 11:46 3.txt -rw-r--r-- 1 root root 0 Mar 18 11:46 4.txt -rw-r--r-- 1 root root 0 Mar 18 11:46 5.txt [root@db01 ~]# echo test {1..3} test1 test2 test3 [root@db01 ~]# echo test {1..3}|xargs -n1 test1 test2 test3 [root@db01 ~]# echo test {1..3}|xargs -n1|sed -r 's#(.*)#\1#g' test1 test2 test3 [root@db01 ~]# echo test {1..3}|xargs -n1|sed -r 's#(.*)#useradd \1#g' useradd test1 useradd test2 useradd test3 [root@db01 ~]# echo test {1..3}|xargs -n1|sed -r 's#(.*)#useradd \1#g' |bash stat /etc/passwd|sed -n '4p' |sed -r 's#^.*(\(0)(.*)/-.*$#\2#g' 或者 stat /etc/passwd|sed -nr '4s#^.*(\(0)(.*)/-.*$#\2#pg' 644
awk命令
内置变量
用途
NR
Number of Record记录行号
NF
Number of Field每行有多少子字段(列)$NF表示最后一列
FS
-F:字段分隔符,每个字段结束标记
OFS
Output Field Separator 输出字段分隔符(awk显示每一列的时候通过什么来分割,默认是空格)
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 awk: 编程语言 GNU/awk 作用: 1.取行 2.取列 3.模糊过滤 4.数据统计 数据运算 5.支持for 循环 if 判断 数组.. 6.格式化输出 sed后向引用 语法结构: awk '模式' file awk '模式{print}' file 其他的命令输出|awk '模式' 模式: 找谁,怎么找 指定行,指定列找,模糊过滤的找 [root@web01 ~]# awk -F: '{print $1,$3,$4}' OFS=: /etc/passwd root:0:0 bin:1:1
1.查找/过滤 ==1.awk按照行进行查找==
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 // $1 ~// 匹配第一列的内容语法结构: sed -n '3p' file awk 'NR==3' file awk的内置变量: NR存放着文件中每行的行号 NR的表达式: == 等于第几行 > 大于第几行 < 小于第几行 >= 等于等于第几行 <= 小于等于第几行 != 不等于 && 并且 || 或者 [root@db01 ~]# cat 1.txt 1 root:x:0:0:root:/root:/bin/bash 2 bin:x:1:1:bin:/bin:/sbin/nologin 3 daemon:x:2:2:daemon:/sbin:/sbin/nologin 4 adm:x:3:4:adm:/var/adm:/sbin/nologin 5 lp:x:4:7:lp:/var/spool/lpd:/sbin/nologin 只显示文件的第3行 [root@db01 ~]# awk 'NR==3' 1.txt 3 daemon:x:2:2:daemon:/sbin:/sbin/nologin 一个等号在系统中称为定义变量 只显示文件中小于3的行 [root@db01 ~]# awk 'NR<3' 1.txt 1 root:x:0:0:root:/root:/bin/bash 2 bin:x:1:1:bin:/bin:/sbin/nologin 只显示文件中大于3的行 [root@db01 ~]# awk 'NR>3' 1.txt 4 adm:x:3:4:adm:/var/adm:/sbin/nologin 5 lp:x:4:7:lp:/var/spool/lpd:/sbin/nologin [root@db01 ~]# awk 'NR<=3' 1.txt 1 root:x:0:0:root:/root:/bin/bash 2 bin:x:1:1:bin:/bin:/sbin/nologin 3 daemon:x:2:2:daemon:/sbin:/sbin/nologin 显示文件中不等于3的行 [root@db01 ~]# awk 'NR!=3' 1.txt 1 root:x:0:0:root:/root:/bin/bash 2 bin:x:1:1:bin:/bin:/sbin/nologin 4 adm:x:3:4:adm:/var/adm:/sbin/nologin 5 lp:x:4:7:lp:/var/spool/lpd:/sbin/nologin 并且和或者: && 并且 案例: 查找大于第2行 并且小于5的行 [root@db01 ~]# awk 'NR>2&&NR<5' 1.txt 3 daemon:x:2:2:daemon:/sbin:/sbin/nologin 4 adm:x:3:4:adm:/var/adm:/sbin/nologin || 或者 案例: 查找小于第2行,或者大于第4行 [root@db01 ~]# awk 'NR<2||NR>4' 1.txt 1 root:x:0:0:root:/root:/bin/bash
==2.模糊过滤文件内容==
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 语法结构: grep '' 文件 sed -n '/内容/p' 文件 awk '/内容/' 文件 awk '//,//' 文件 awk '/10:00/,/11:00/' access.log 案例1.查找包含root的行 [root@db01 ~]# awk '/root/' 1.txt 1 root:x:0:0:root:/root:/bin/bash 案例2.查找以1开头的行 [root@db01 ~]# awk '/^r/' 1.txt root:x:0:0:root:/root:/bin/bash [root@db01 ~]# awk '/h$/' 1.txt 1 root:x:0:0:root:/root:/bin/bash [root@db01 ~]# awk '/^[1-3]/' 1.txt 1 root:x:0:0:root:/root:/bin/bash 2 bin:x:1:1:bin:/bin:/sbin/nologin 3 daemon:x:2:2:daemon:/sbin:/sbin/nologin 案例3.区间范围 工作中取时间范围较多 [root@db01 ~]# awk '/^2/,/^4/' 1.txt 2 bin:x:1:1:bin:/bin:/sbin/nologin 3 daemon:x:2:2:daemon:/sbin:/sbin/nologin 4 adm:x:3:4:adm:/var/adm:/sbin/nologin 注意: 三剑客支持扩展正则写法 grep -E 或者egrep sed -r awk 默认支持扩展正则
2.awk取列 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 88 89 90 91 92 93 94 95 96 97 98 99 100 101 102 103 104 105 106 107 108 109 110 111 112 113 114 115 116 117 118 119 120 121 122 123 124 125 126 127 128 129 130 131 132 133 134 135 136 137 138 139 140 141 142 143 144 145 146 147 148 149 150 151 152 153 154 155 156 157 158 159 160 161 162 163 164 165 166 167 168 169 170 171 172 173 174 175 176 177 178 179 180 181 182 183 184 185 186 187 188 189 190 191 192 193 194 195 196 197 198 199 200 201 202 203 204 205 语法结构: awk '{print $n}' file $0 awk的内置变量里面存放着每行的内容,(可以判断awk执行的哪些行内容)$1 表示第1列 默认以空格和tab键为分隔符,如果文件中没有空格和tab键则文件内容被当做第一列$2 表示第2列,逗号 内置变量,表示空格 NF 表示最后一列的列号 $NF 表示最后一列的内容注意: 所有的字符串在awk中被识别为变量,所以输出字符串必须加双引号 awk指定分隔符: 默认以tab键或空格分隔 -F awk -F: awk -F ":" [root@web01 zzz]# cat /etc/passwd|awk -F '[ :]+' 'NR>5&&NR<8{print $1,$2}' sync xshutdown x [root@web01 zzz]# cat /etc/passwd|awk -F '[ :]+' 'NR>5&&NR<8{print $1,$2,$0}' sync x sync :x:5:0:sync :/sbin:/bin/syncshutdown x shutdown:x:6:0:shutdown:/sbin:/sbin/shutdown [root@web01 zzz]# awk -F: '{print NF}' 1.txt 7 7 7 7 案例1.显示文件的第一列 [root@db01 ~]# cat 1.txt root:x:0:0:root:/root:/bin/bash bin:x:1:1:bin:/bin:/sbin/nologin daemon:x:2:2:daemon:/sbin:/sbin/nologin adm:x:3:4:adm:/var/adm:/sbin/nologin lp:x:4:7:lp:/var/spool/lpd:/sbin/nologin sync :x:5:0:sync :/sbin:/bin/sync案例1.打印出第一列 [root@db01 ~]# awk -F: '{print $1}' 1.txt root bin daemon adm lp sync 案例2.显示文件的第1列和第3列 [root@db01 ~]# awk -F: '{print $1,$3}' 1.txt root 0 bin 1 daemon 2 adm 3 lp 4 sync 5[root@db01 ~]# awk -F: '{print $1"---"$3}' 1.txt root---0 bin---1 daemon---2 adm---3 lp---4 sync---5 案例.先输出第3列 后面输出第1列 [root@db01 ~]# awk -F: '{print $3" "$1}' 1.txt 0 root 1 bin 2 daemon 3 adm 4 lp 5 sync 案例: 取出最后一列的内容: [root@db01 ~]# awk -F: '{print $NF}' 1.txt /bin/bash /sbin/nologin /sbin/nologin /sbin/nologin /sbin/nologin /bin/sync [root@web01 zzz]# df -h Filesystem Size Used Avail Use% Mounted on /dev/sda3 19G 1.9G 17G 11% / devtmpfs 476M 0 476M 0% /dev tmpfs 487M 0 487M 0% /dev/shm tmpfs 487M 20M 467M 5% /run tmpfs 487M 0 487M 0% /sys/fs/cgroup /dev/sda1 497M 120M 378M 25% /boot tmpfs 98M 0 98M 0% /run/user/0 案例: 取出磁盘中的第5列 [root@db01 ~]# df -h|awk '{print $5}' Use% 11% 0% 0% 5% 0% 25% 0% 案例: 取出sda3的行的方法 [root@db01 ~]# df -h|grep '/$' /dev/sda3 19G 1.9G 17G 11% / [root@db01 ~]# df -h|grep 'sda3' /dev/sda3 19G 1.9G 17G 11% / [root@db01 ~]# df -h|sed -n '2p' /dev/sda3 19G 1.9G 17G 11% / [root@db01 ~]# df -h|sed -n '/sda3/p' /dev/sda3 19G 1.9G 17G 11% / [root@db01 ~]# df -h|sed -n '/\/$/p' /dev/sda3 19G 1.9G 17G 11% / [root@db01 ~]# df -h|awk 'NR==2' /dev/sda3 19G 1.9G 17G 11% / [root@db01 ~]# df -h|awk '/\/$/' /dev/sda3 19G 1.9G 17G 11% / [root@db01 ~]# df -h|awk '/sda3/' /dev/sda3 19G 1.9G 17G 11% / [root@db01 ~]# df -h|awk '{print $(NF-1)}' Mounted 11% 0% 0% 5% 0% 25% 0% 取出每行的倒数第2列的内容 [root@db01 ~]# cat 1.txt root:x:0:0:root:/root:/bin/bash bin:x:1:1:bin:/bin:/sbin/nologin daemon:x:2:2:daemon:/sbin:/sbin/nologin adm:x:3:4:adm:/var/adm:/sbin/nologin lp:x:4:7:lp:/var/spool/lpd:/sbin/nologin sync :x:5:0:sync :/sbin:/bin/sync[root@web01 zzz]# awk -F: '{print $(NF-1)}' 1.txt /root /bin /sbin /var/adm /var/spool/lpd /sbin 案例.指定多分隔符 [root@db01 ~]# cat 2.txt root:x:0:0:root:/oldboy:/bin/bash [root@db01 ~]# awk -F ":/" '{print $2}' 2.txt oldboy 案例.取出test 和oldboy 案例.+连续出现1次及1次以上的作为1个整体 [root@db01 ~]# cat 2.txt root:x:0:0:test :/oldboy:/bin/bash [root@db01 ~]# awk -F "[:/]+" '{print $5,$6}' 2.txt test oldboy理解正则表达式+ [root@db01 ~]# echo ---test -+oldboy++::|awk -F "-" '{print $4}' test [root@db01 ~]# echo ---test -+oldboy++::|awk -F "[-]+" '{print $2}' test [root@db01 ~]# echo ---test -+oldboy++::|awk -F "[-+]" '{print $6}' oldboy [root@db01 ~]# echo ---test -+oldboy++::|awk -F "[-+]+" '{print $3}' oldboy [root@web01 ~]# echo ---test -+--oldboy++::|awk -F "[-+]" '{print $4}' test [root@web01 ~]# echo ---test -+--oldboy++::|awk -F "[-+]" '{print $8}' oldboy [root@web01 ~]# echo ---test -+--oldboy++::|awk -F "[-+]" '{print $10}' :: [root@web01 ~]# echo ---test -+--oldboy++::|awk -F "[-+]+" '{print $2,$3,$4}' test oldboy ::扩展:让取出的列排列整齐 column -t [root@web01 ~]# awk -F: '{print $1,$3}' /etc/passwd|column -t root 0 bin 1 daemon 2 adm 3 lp 4 sync 5shutdown 6
3.awk模式+动作
1 2 3 4 5 6 [root@web01 ~]# cat /etc/services |wc -l 11176 [root@web01 ~]# awk '{i++}END{print i}' /etc/services 11176
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 [root@db01 ~]# cat 1.txt 1 root:x:0:0:root:/root:/bin/bash 2 bin:x:1:1:bin:/bin:/sbin/nologin 3 daemon:x:2:2:daemon:/sbin:/sbin/nologin 4 adm:x:3:4:adm:/var/adm:/sbin/nologin :5 lp:x:4:7:lp:/var/spool/lpd:/sbin/nologin [root@db01 ~]# awk 'NR==3' 1.txt 3 daemon:x:2:2:daemon:/sbin:/sbin/nologin [root@db01 ~]# awk -F: 'NR==3{print $3 }' 1.txt 2 案例2.取出用户名和最后一列 [root@db01 ~]# cat 1.txt 1 root:x:0:0:root:/root:/bin/bash 2 bin:x:1:1:bin:/bin:/sbin/nologin 3 daemon:x:2:2:daemon:/sbin:/sbin/nologin 4 adm:x:3:4:adm:/var/adm:/sbin/nologin 5 lp:x:4:7:lp:/var/spool/lpd:/sbin/nologin [root@db01 ~]# awk -F "[ :]" '{print $2,$NF }' 1.txt root /bin/bash bin /sbin/nologin daemon /sbin/nologin adm /sbin/nologin lp /sbin/nologin [root@db01 ~]# awk -F "[ :]" '{print $2"\t"$NF }' 1.txt root /bin/bash bin /sbin/nologin daemon /sbin/nologin adm /sbin/nologin lp /sbin/nologin 案例.取出/磁盘使用行的 第4列 指定行+动作 [root@web01 zzz]# df -h Filesystem Size Used Avail Use% Mounted on /dev/sda3 19G 1.9G 17G 11% / devtmpfs 476M 0 476M 0% /dev tmpfs 487M 0 487M 0% /dev/shm tmpfs 487M 20M 467M 5% /run tmpfs 487M 0 487M 0% /sys/fs/cgroup /dev/sda1 497M 120M 378M 25% /boot tmpfs 98M 0 98M 0% /run/user/0 [root@web01 zzz]# df -h|awk 'NR==2' /dev/sda3 19G 1.9G 17G 11% / 模糊过滤+动作 [root@db01 ~]# df -h|awk '/\/$/{print $4,$1}' 17G /dev/sda3 [root@db01 ~]# df -h|awk '/sda3/{print $4,$1}' 17G /dev/sda3 案例.取出dev相关的行的第1行和第2行 [root@web01 zzz]# df -h|awk '/sda3/,/devtmpfs/' /dev/sda3 19G 1.9G 17G 11% / devtmpfs 476M 0 476M 0% /dev cat -n /etc/passwd|awk 'NR>5&&NR<8' 6 sync :x:5:0:sync :/sbin:/bin/sync 7 shutdown:x:6:0:shutdown:/sbin:/sbin/shutdown [root@web01 zzz]# cat /etc/passwd|awk -F '[ :]+' 'NR>5&&NR<8{print $1,$2}' sync xshutdown x
4.字符串对比 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 扩展: 字符串比对 [root@db01 ~]# cat 1.txt root:x:0:0:root:/root:/bin/bash bin:x:1:1:bin:/bin:/sbin/nologin daemon:x:2:2:daemon:/sbin:/sbin/nologin root:hehe:xx adm:x:3:4:adm:/var/adm:/sbin/nologin lp:x:4:7:lp:/var/spool/lpd:/sbin/nologin [root@db01 ~]# awk -F: '$NF=="/bin/bash"' 1.txt root:x:0:0:root:/root:/bin/bash 查找出以ro开头的行 [root@db01 ~]# awk -F: '/^ro/' 1.txt root:x:0:0:root:/root:/bin/bash root:hehe:xx [root@web01 zzz]# awk -F: '$5 ~ /^r/' 1.txt root:x:0:0:root:/root:/bin/bash [root@web01 zzz]# awk -F: '$5 ~ /t$/' 1.txt root:x:0:0:root:/root:/bin/bash 数字比较: [root@db01 ~]# awk -F: '$3>0' 1.txt bin:x:1:1:bin:/bin:/sbin/nologin daemon:x:2:2:daemon:/sbin:/sbin/nologin adm:x:3:4:adm:/var/adm:/sbin/nologin lp:x:4:7:lp:/var/spool/lpd:/sbin/nologin [root@db01 ~]# awk -F: '$3<2' 1.txt root:x:0:0:root:/root:/bin/bash bin:x:1:1:bin:/bin:/sbin/nologin [root@db01 ~]# awk -F: '$3<=2' 1.txt root:x:0:0:root:/root:/bin/bash bin:x:1:1:bin:/bin:/sbin/nologin daemon:x:2:2:daemon:/sbin:/sbin/nologin [root@db01 ~]# 成绩单统计:(假定第二列是成绩) 案例。大于等于90的人数 [root@db01 ~]# awk '$2>=90' 1.txt|wc -l 16 案例. 大于等于80并且小于90的人数 [root@db01 ~]# awk '$2>=80&&$2<90' 1.txt |wc -l 29 案例.小于60分的人数 [root@db01 ~]# awk '$2<60' 1.txt|wc -l
5.awk替换 1 2 3 4 5 6 awk '{ sub(/apple/, "pear", $1); print }' file.txt awk '{ gsub(/apple/, "pear", $1); print }' file.txt awk '{ sub(/apple/, "pear", $1); print }' file.txt > new_file.txt
==总结== 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 1.awk取行 awk 'NR==3' file NR== NR!= NR>= NR<= NR> NR< && || 2.awk模糊过滤 awk '/过滤的内容/' file awk '//,//' file 支持正则 3.awk取列 awk '{print $1}' file awk '{print $NF}' file 最后一列 4.awk指定分隔符 awk -F: awk -F ":" awk -F "[:/]+" 5.awk模式+动作 awk 'NR==6{print $3}' awk '//{print $3}' 6.字符串比较 awk '$3=="root"' file awk '$3!="root"' file 不等于 7.awk数值比较 awk '$3==0' file awk '$3>90' file awk '$3>80&&$3<90' file || 或者
循环&判断 ==for循环==
for i in 1 2 3
do
echo $i
done
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 for (i=1;i<10;i++)do echo $i done for (i=1;i<10;i++)print i案例 1+...+100 [root@web01 zzz]# awk 'BEGIN{for(i=1;i<=100;i++)sum+=i;print sum}' 5050 awk 'BEGIN{ for(i=1;i<=100;i++) sum+=i; print sum }'
==if判断==
1 2 3 4 5 6 7 8 9 10 11 12 if { $? -eq 0 };then echo "正常" else echo "命令执行错误" fi if (条件) print "abc" else print "cc" awk -F: '{ if ($3 > 100) { print "大于100: " $0 } else { print "小于等于100: " $0 } }' /etc/passwd
awk正则
支持扩展正则
awk可以精确到某一列 ,某一列包含的内容/不包含的内容
~ 包含
!~不包含
正则
awk正则
^表示以…开头的行
某一列开的行 $3~/^root/
$表示以…结尾的行
某一列开的行 $3~/bash$/
^$表示空行
1 2 3 4 5 6 7 8 9 10 11 12 [root@web01 ~]# awk -F: '$1~/^root/' /etc/passwd root:x:0:0:root:/root:/bin/bash [root@web01 ~]# awk -F: '$1~/root/{print $1,$3,$5}' /etc/passwd root 0 root [root@web01 ~]# awk -F: '$3~/^[13]/' /etc/passwd [root@web01 ~]# awk -F: '$3~/^(1|3)/' /etc/passwd bin:x:1:1:bin:/bin:/sbin/nologin adm:x:3:4:adm:/var/adm:/sbin/nologin operator:x:11:0:operator:/root:/sbin/nologin
特殊模式BEGIN{} END{}
模式
含义
应用场景
BEGIN{}
里面内容会在awk读取文件之前 执行
1)进行简单统计,不涉及读取文件
END{}
里面内容会在awk读取文件之后 执行
1)awk进行统计,一般过程,先进行计算,最后END里面输出 >结果
统计方法
简写
应用场景
i=i+1
i++
计数,统计次数
sum=sum+i
sum+=i
求和,累加
1 2 3 [root@web01 ~]# awk '/^$/{i++}END{print i}' /etc/services 17
awk数组
shell数组
awk数组
形式
array[0]=oldboy array[1]=996
array[0]=oldboy array[1]=996
使用
echo $array[0] $array[1]
print $array[0] $array[1]
批量输出数组内容
for i in ${array[*]}
for(i in array)
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 awk数组专用循环,变量获取到的是数组的下标,想要获取数组内容,array[i] [root@web01 ~]# awk 'BEGIN{a[0]=123;a[1]="creat"; for(i in a) print i,a[i]}' 0 123 1 creat [root@web01 ~]# cat 1.txt http://www.driverzeng.com/index.html http://www.driverzeng.com/1.html http://post.driverzeng.com/index.html http://mp3.driverzeng.com/index.html http://www.driverzeng.com/3.html http://post.driverzeng.com/2.html [root@web01 ~]# awk -F '[./]+' '{array[$2]++}END{for(i in array)print i,array[i]' 1.txt www 3 mp3 1 post 2 array[$2 ]++ ==>[ ]里是数组想要统计的内容 {for (i in array) ==>循环数组 print i ==>这里的i是[ ]里的内容array[i] ==>数组+下标表示的是内容,这里的内容表示的是次数 [root@web02 ~]# awk '{array[$10]++}END{for(i in array)print $1,i,array[i]}' access.log|sort -nrk3 115.223.23.182 200 710 115.223.23.182 304 250 115.223.23.182 302 223 115.223.23.182 404 186 115.223.23.182 301 65 115.223.23.182 403 45 115.223.23.182 503 4
==案例==
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 [root@web01 ~]# cat 123.txt Zeng Laoshi 133411023 :110:100:75 Deng Ziqi 44002231 :250:10:88 Zhang Xinyu 877623568 :120:300:200 Gu Linazha 11029987 :120:30:79 Di Lireba 253097001 :220:100:200 Jiang Shuying 535432779 :309:10:2 Ju Jingyi 68005178 :130:280:385 Zhang Yuqi 376788757 :500:290:33 Wen Zhang 259872003 :100:200:300 [root@web01 ~]# awk -F '[ :]+' '/^Zhang/{print $1,$2" 第二次捐款:"$5}' 123.txt Zhang Xinyu 第二次捐款:300 Zhang Yuqi 第二次捐款:290 [root@web01 ~]# awk '$3~ /^25/{print $1,$2,$3}' 123.txt Di Lireba 253097001 Wen Zhang 259872003 [root@web01 ~]# awk '$3~ /(1|3)$/{print $1,$2,$3}' 123.txt Zeng Laoshi 133411023 Deng Ziqi 44002231 Di Lireba 253097001 Wen Zhang 259872003 [root@web01 ~]# awk '{gsub(":","$");print $0 }' 123.txt Zeng Laoshi 133411023 $110$100$75 Deng Ziqi 44002231 $250$10$88 Zhang Xinyu 877623568 $120$300$200 Gu Linazha 11029987 $120$30$79 Di Lireba 253097001 $220$100$200 Jiang Shuying 535432779 $309$10$2 Ju Jingyi 68005178 $130$280$385 Zhang Yuqi 376788757 $500$290$33 Wen Zhang 259872003 $100$200$300